
The Covid-19 pandemic happened in an era that is filled with data overload, fake news, steep inequality, turbulent political currents, as well as a generation of the most active netizens across the globe. This project was launched in March 2020 to document, critically investigate, and generate a reproducible digital archive of this historical episode of the 21st century. Honing in on the humanistic analysis in exploring this large-scale quantitative corpus, we hope to highlight the societal, sociolinguistical, and geographical patterns of English- and Spanish-language Twitter discourse of this global public health crisis.
Our team consists of a diverse scholar community of faculty, PhD Candidates, and researchers from the University of Miami (Florida, USA) and CONICET (Argentina). With an small grant from the College of Arts and Science at the University of Miami, we are able to gather and analyze data from crowdsourced resources and Twitter in English and Spanish.
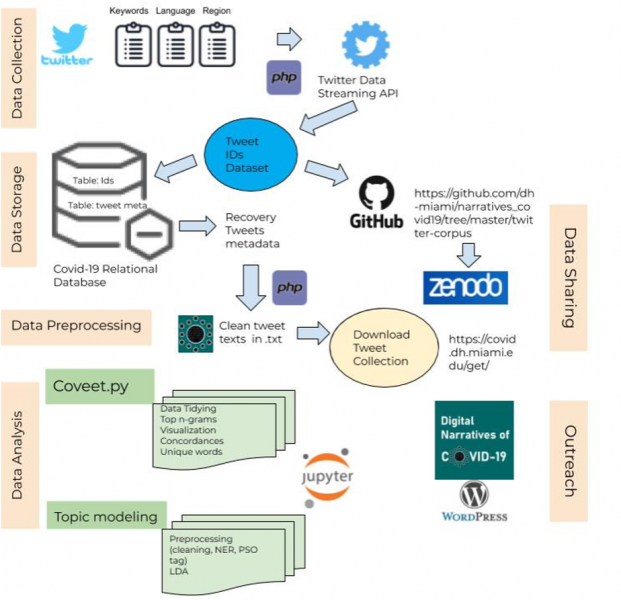
In addition to our open-access corpus that is accessible through our website, Github, our Beta API, and Zenodo, we have also created a collection of Python scripts in frequency analysis, concordance analysis, sentiment analysis, and topic modeling that are available for download.
We update our progress and write technical tutorials from hydrating Tweet IDs to demonstrating our Python scripts in our Blog section. You may also see our publications in the Journal of Open Humanities Data with more forthcoming.
We welcome questions, critiques, suggestions, and collaborations. Please feel free to contact us and we look forward to hearing from you!