- How to run the coveet.py scriptThe Coveet.py is hosted in our GitHub repository of the Digital Narratives of Covid-19 project. In the main page of the repository, https://github.com/dh-miami/narratives_covid19, there are two different buttons that allow to run a Binder environment: one of them launches the Frequency analysis Jupyter notebook, and the other one the Sentiment Analysis script. Let’s first launch… Read more: How to run the coveet.py script
- Reflections on quantified data: #ScholarStrike in the context of COVID-19
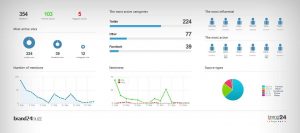 Although the COVID-19 pandemic created a truly shared global context for the first time in years, it soon began to coexist with the local reality of each country. Twitter, as expected, was no stranger to this, and certain hashtags soon began to appear that account for this “localization” process of the pandemic (for example, in… Read more: Reflections on quantified data: #ScholarStrike in the context of COVID-19
Although the COVID-19 pandemic created a truly shared global context for the first time in years, it soon began to coexist with the local reality of each country. Twitter, as expected, was no stranger to this, and certain hashtags soon began to appear that account for this “localization” process of the pandemic (for example, in… Read more: Reflections on quantified data: #ScholarStrike in the context of COVID-19 - Pensar los datos cuantificados: #ScholarStrike en el contexto de la COVID-19Si bien la pandemia de COVID-19 impuso por primera vez en años un contexto global compartido, este pronto comenzó a convivir con la coyuntura local de cada país. Twitter, como es esperable, no fue ajeno a ello, y pronto comenzaron a surgir hashtags específicos que deban cuenta de ese proceso de localización de la pandemia… Read more: Pensar los datos cuantificados: #ScholarStrike en el contexto de la COVID-19
- Acceso a nuestra colección de TwitterEstamos felices de anunciar finalmente el lanzamiento de la interfaz para descargar una colección de tweets relacionados con la pandemia de Covid-19. Puedes elegir un rango de fecha, un área (México, Argentina, Colombia, Perú, Ecuador, España, área de Miami), y el idioma (sólo para el área de Miami, en inglés y español). https://covid.dh.miami.edu/get/ Los textos… Read more: Acceso a nuestra colección de Twitter
- Access our Twitter Collection
 We are happy to finally launch the interface to download a collection of tweets related to the Covid-19 pandemic. You can choose a range date, an area (Mexico, Argentina, Colombia, Perú, Ecuador, Spain, Miami area), and language (only for the Miami area, in English and Spanish). https://covid.dh.miami.edu/get/ The texts are processed by removing accents, punctuations,… Read more: Access our Twitter Collection
We are happy to finally launch the interface to download a collection of tweets related to the Covid-19 pandemic. You can choose a range date, an area (Mexico, Argentina, Colombia, Perú, Ecuador, Spain, Miami area), and language (only for the Miami area, in English and Spanish). https://covid.dh.miami.edu/get/ The texts are processed by removing accents, punctuations,… Read more: Access our Twitter Collection - Frequency Analysis for South Florida (April – June)
 This post compares the top 30 most frequent words and the top 20 hashtags in our Twitter English and Spanish corpora of South Florida from April 25th to June 25th, 2020. We divided it into 2 four-week periods to analyze broad trends and themes in the discourse. For our corpus criteria as well as for… Read more: Frequency Analysis for South Florida (April – June)
This post compares the top 30 most frequent words and the top 20 hashtags in our Twitter English and Spanish corpora of South Florida from April 25th to June 25th, 2020. We divided it into 2 four-week periods to analyze broad trends and themes in the discourse. For our corpus criteria as well as for… Read more: Frequency Analysis for South Florida (April – June) - Outbreak Topics: Topic modeling of COVID-19
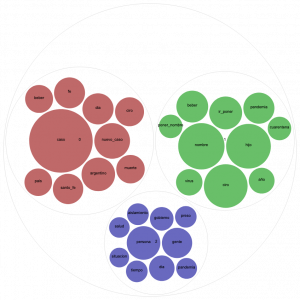 In this post, we will present another way to explore our dataset of tweets on Covid-19. We intend to detect emerging topics of interest for our study of the social narratives about the pandemic. For this, we will perform unsupervised machine learning using different Python libraries. In this case, we work with data in Spanish,… Read more: Outbreak Topics: Topic modeling of COVID-19
In this post, we will present another way to explore our dataset of tweets on Covid-19. We intend to detect emerging topics of interest for our study of the social narratives about the pandemic. For this, we will perform unsupervised machine learning using different Python libraries. In this case, we work with data in Spanish,… Read more: Outbreak Topics: Topic modeling of COVID-19 - Los temas de la crisis: topic modeling sobre la COVID-19
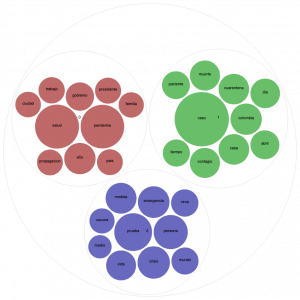 En este post, presentaremos otra manera de explorar nuestro dataset de tweets sobre el Covid-19 con el objetivo de detectar temas o tópicos emergentes de interés para nuestro estudio de las narrativas sociales acerca de la pandemia. Para ello, realizamos un procesamiento de aprendizaje automático no supervisado con la ayuda de diferentes librerías para Python.… Read more: Los temas de la crisis: topic modeling sobre la COVID-19
En este post, presentaremos otra manera de explorar nuestro dataset de tweets sobre el Covid-19 con el objetivo de detectar temas o tópicos emergentes de interés para nuestro estudio de las narrativas sociales acerca de la pandemia. Para ello, realizamos un procesamiento de aprendizaje automático no supervisado con la ayuda de diferentes librerías para Python.… Read more: Los temas de la crisis: topic modeling sobre la COVID-19 - ¿Qué pueden decirnos las publicaciones académicas sobre el COVID-19 y la Educación?
 La aparición del coronavirus ha puesto en nuestro lenguaje cotidiano nuevos términos, como pandemia o infodemia. Este último, de acuerdo a Wikipedia, puede ser definido como: “El término infodemia se emplea para referirse a la sobreabundancia de información (ya sea rigurosa o falsa) sobre un tema concreto, como por ejemplo en el caso del coronavirus.… Read more: ¿Qué pueden decirnos las publicaciones académicas sobre el COVID-19 y la Educación?
La aparición del coronavirus ha puesto en nuestro lenguaje cotidiano nuevos términos, como pandemia o infodemia. Este último, de acuerdo a Wikipedia, puede ser definido como: “El término infodemia se emplea para referirse a la sobreabundancia de información (ya sea rigurosa o falsa) sobre un tema concreto, como por ejemplo en el caso del coronavirus.… Read more: ¿Qué pueden decirnos las publicaciones académicas sobre el COVID-19 y la Educación? - What can academic journals tell us about COVID-19 and Education?The Covid situation has put new terms into our everyday vocabulary, terms such as pandemic or infodemic. This last one, according to Wiktionary can be defined as: Blend of information + epidemic Noun infodemic (plural infodemics) (informal) An excessive amount of information concerning a problem such that the solution is made more difficult. (informal) A… Read more: What can academic journals tell us about COVID-19 and Education?
- Analizar un corpus de Twitter con Voyant (I)
 La primera etapa del trabajo con datos es conocer con qué corpus se va a trabajar. Nuestro proyecto, por ejemplo, se interesa especialmente por el contexto lingüístico y humanístico sobre el discurso que se generó en Twitter debido a la pandemia de Covid-19. Algunas preguntas que nos hicimos, desde el inicio, incluyen la proporción de… Read more: Analizar un corpus de Twitter con Voyant (I)
La primera etapa del trabajo con datos es conocer con qué corpus se va a trabajar. Nuestro proyecto, por ejemplo, se interesa especialmente por el contexto lingüístico y humanístico sobre el discurso que se generó en Twitter debido a la pandemia de Covid-19. Algunas preguntas que nos hicimos, desde el inicio, incluyen la proporción de… Read more: Analizar un corpus de Twitter con Voyant (I) - ¿Cómo hidratar un conjunto de Tweets?
 El discurso público generado en Twitter es uno de los principales focos de atención en nuestro proyecto de investigación. Asimismo, la gran cantidad de datos de Twitter ha atraído el interés de investigadores de disciplinas y campos diversos para explorar diferentes aspectos de la sociedad. Esta entrada se concibe a modo de tutorial sobre cómo… Read more: ¿Cómo hidratar un conjunto de Tweets?
El discurso público generado en Twitter es uno de los principales focos de atención en nuestro proyecto de investigación. Asimismo, la gran cantidad de datos de Twitter ha atraído el interés de investigadores de disciplinas y campos diversos para explorar diferentes aspectos de la sociedad. Esta entrada se concibe a modo de tutorial sobre cómo… Read more: ¿Cómo hidratar un conjunto de Tweets? - Analyzing a Twitter Corpus with Voyant (I)The first step of working with data is to get to know your corpus. Our project, for instance, is most concerned with the linguistic and humanistic contexts in the Twitter discourses generated by the Covid-19 pandemic. Some starting “get-to-know-you” questions we are interested in about our corpus include the trend of daily corpus length, most… Read more: Analyzing a Twitter Corpus with Voyant (I)
- How to “hydrate” a TweetSet?Twitter public discourse is one of our project’s primary research concerns. Twitter’s rich data has also drawn more and more researchers from various disciplines and fields to explore different aspects of society. This blog post serves as a tutorial of using DocNow Hydrator to “hydrate” tweets. Our project, as we explained, is offering a series… Read more: How to “hydrate” a TweetSet?
- Un conjunto de datos de Twitter para la narrativa digital
 A finales de abril empezamos a familiarizarnos con la API de Twitter y a preguntarnos cómo capturar las conversaciones públicas que están ocurriendo en esta red social. Entendimos rápidamente que necesitábamos un plan y una metodología para organizar nuestro corpus, conseguir nuestros objetivos, y dividir las diferentes tareas entre los miembros del equipo. Los conjuntos… Read more: Un conjunto de datos de Twitter para la narrativa digital
A finales de abril empezamos a familiarizarnos con la API de Twitter y a preguntarnos cómo capturar las conversaciones públicas que están ocurriendo en esta red social. Entendimos rápidamente que necesitábamos un plan y una metodología para organizar nuestro corpus, conseguir nuestros objetivos, y dividir las diferentes tareas entre los miembros del equipo. Los conjuntos… Read more: Un conjunto de datos de Twitter para la narrativa digital
 Digital Narratives of Covid-19
Digital Narratives of Covid-19