The Coveet.py is hosted in our GitHub repository of the Digital Narratives of Covid-19 project.
In the main page of the repository, https://github.com/dh-miami/narratives_covid19, there are two different buttons that allow to run a Binder environment: one of them launches the Frequency analysis Jupyter notebook, and the other one the Sentiment Analysis script.
Let’s first launch the Frequency Analysis by clicking to the “launch | binder”:
The Binder platform will open up and it can take some minutes to prepare:

Once is ready, you will see the Jupyter notebook, and you can start running the code. Read carefully all the narrative and try running every one of the chunks of code:
Once the set up is complete (0. Setting Up), the first step begins. The first time you can try running the code as is, but the idea is everyone can customize the query following their research interests:
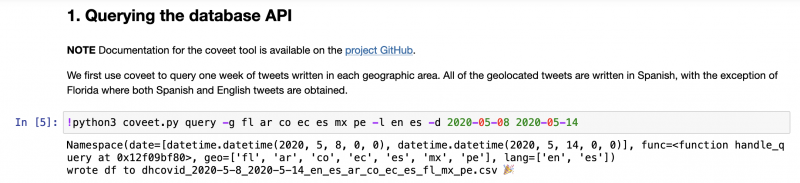
-g stands for geography and -l language, so you will need to change the query code. If you want all tweets from Ecuador in Spanish from May 2020 until July 2021, the query will need to be: !python3 coveet.py query -g ec -l es -d 2020-05-01 2020-07-31 This query would then create a file called dhcovid_2020-5-1_2020-7-30_es_ec.csv
It is important that you run a chunk of code at at a time and wait that it appears a number between brackets. If you see the asteriks [*] means that the script is still running.
How to obtain Concordances?
Once the Jupyter notebook is running in Binder, you just have to look for the Concordance script. To do so, you need to go up the tree of the repository by changing the URL, for example, if your current Binder URL is https://hub.gke2.mybinder.org/user/dh-miami-narratives_covid19-dh1w6ul9/notebooks/scripts/freq_analysis/coveet_frequency.ipynb you need to change it to https://hub.gke2.mybinder.org/user/dh-miami-narratives_covid19-dh1w6ul9/tree/
Then, you have to look for move to scripts/freq_analysis and open the coveet_concordance.ipynb:
You will have to change the dates, the region and the language that you are researching (line 3), for example, in my case should be: !python coveet.py query -g es -l es -d 2020-05-08 2020-05-14
You can ignore this line: !conda activate blueberry; python coveet.py query -g fl ar co ec es mx pe -l en es -d 2020-05-08 2020-05-14
Remember to substitute the file that you have created when doing the query: df = pd.read_csv(‘dhcovid_2020-5-8_2020-5-14_es_es.csv’, index_col=0)
Finally, to look for the terms you want modify the step 7:

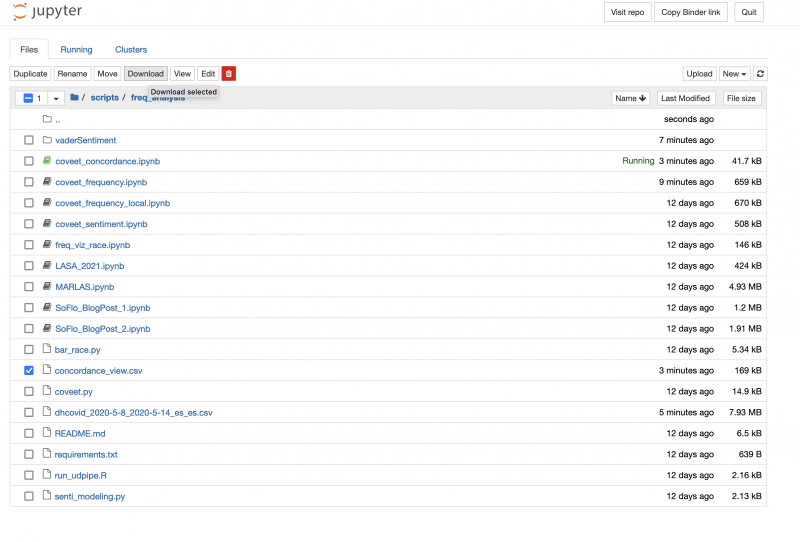
And then you will be able to download your concordances in the file concordance_view.csv (go up to the tree and download it).