
Si bien la pandemia de COVID-19 impuso por primera vez en años un contexto global compartido, este pronto comenzó a convivir con la coyuntura local de cada país. Twitter, como es esperable, no fue ajeno a ello, y pronto comenzaron a surgir hashtags específicos que deban cuenta de ese proceso de localización de la pandemia (por ejemplo, en Argentina, #coronacrisis, en referencia al derrumbe financiero a consecuencia de una larga cuarentena y una débil economía heredada del periodo anterior). No obstante, otros hashtags menos representativos de la situación sanitaria pronto comenzaron a resignificarse, e incluso a surgir, dentro de este contexto. Para los Estados Unidos, este fue el caso de #BlackLivesMatter y #ScholarStrike.
En este post buscamos investigar en las particularidades de este último, siguiendo la línea de reflexiones que propusimos en nuestro post anterior (What can academic journals tell us about COVID-19 and Education?), es decir, utilizar plataformas de análisis cuantitativo (en el post anterior usamos AVOBMAT ) desarrolladas por terceros para realizar un ejercicio de minería de datos, a la vez que evaluamos las funcionalidades y limitaciones de la herramienta.
El caso de #ScholarStrike nos pareció ideal para trabajar con una herramienta “a medida”, ya que es un hashtag que tuvo fuerte presencia durante un tiempo acotado (previo a la iniciativa, durante la misma y algunos días posteriores).
Para quienes no están al tanto de las noticias del Norte, Scholar Strike fue un movimiento comunitario en las universidades que buscó reconocer el creciente número de muertes de Afroamericanos y otras minorías por el uso excesivo de la violencia y la fuerza por parte de la policía. Durante dos días, del 8 al 9 de septiembre, profesores, personal universitario, estudiantes e incluso administrativos se apartaron de sus deberes y clases regulares para participar en clases (en algunos casos, abiertas) sobre la injusticia racial, la vigilancia policial y el racismo en Estados Unidos. Las universidades de Canadá realizaron su propia Scholar Strike del 9 al 10 de septiembre. En el sitio oficial del movimiento, se puede leer más sobre los fundamentos de Scholar Strike, asi como en su canal de YouTube, donde diferentes académicos colocaron clases abiertas y recursos. El sitio oficial también contiene una lista de recursos textuales y audiovisuales que pueden ser utilizados en las clases así como información sobre la cobertura de Scholar Strike en los medios. Scholar Strike Canada también creó un sitio web oficial, que incluye los detalles del programa de actividades, recursos y links a organizaciones que apoyaron la iniciativa.
Nuestro objetivo fue hacer minería sobre este hashtag en Twitter, buscando asimismo coincidencias terminológicas con otros directamente relacionados, como #BlackLivesMatter, y con algunos más ligados a la crisis del coronavirus.
Para ello, echamos mano de dos plataformas comerciales de minería de Twitter: Brand24 y Audiense. Evidentemente, estas herramientas no son académicas, pero, como veremos mas adelante, se adaptan perfectamente al tipo de trabajo que queremos hacer con relación al análisis de datos cuantificados.
El sitio oficial de Brand24 describe a la plataforma como una “herramienta de monitoreo de redes sociales y páginas web con potentes posibilidades de análisis.” (Brand24 is a web and social media monitoring tool with powerful analytics). La herramienta busca las palabras clave que el usuario proporciona y las analiza en varios niveles. La herramienta está principalmente orientada para análisis de marcas y el uso de esos datos en marketing digital. Por otra parte, Audiense, según describe su página oficial, “proporciona información detallada sobre cualquier audiencia para impulsar estrategia de marketing social con datos procesables y enriquecidos en tiempo real con el fin de ofrecer resultados comerciales genuinos” . Cabe destacar, como puede verse por las descripciones oficiales de las herramientas, que ambas han sido desarrolladas para ser utilizadas en proyectos empresariales, aunque se adaptan, claro está, a cualquier tipo de búsqueda en redes sociales.
La labor con estas plataformas es radicalmente opuesta a la que venimos realizando en este proyecto. Si en la interacción con nuestra base de datos, establecemos un proceso de filtro y curaduría de los datos, para luego proceder al análisis a través de distintas herramientas y métodos (frecuencia de términos, topic modeling), aquí son pocos los filtros que podemos dar a la plataforma (elegir las redes, establecer variables de días) y es la plataforma la que arroja diariamente una serie de resultados que son asimismo interpretados en un análisis automático en la forma de porcentajes y visualizaciones e infografías.
Como decíamos, usamos las plataformas Brand24 y Audiense en su versión trial de 7 días. A grandes rasgos, comparativamente, Brand24 es una plataforma bastante superadora a Audiense. Al introducir las mismas búsquedas, lo primero que notamos fue que Audiense presenta un sesgo altísimo frente a la información. Todos los tweets que levantamos con el hashtag #ScholarStrike eran negativos. Todos provenían de seguidores de Trump o del presidente mismo.
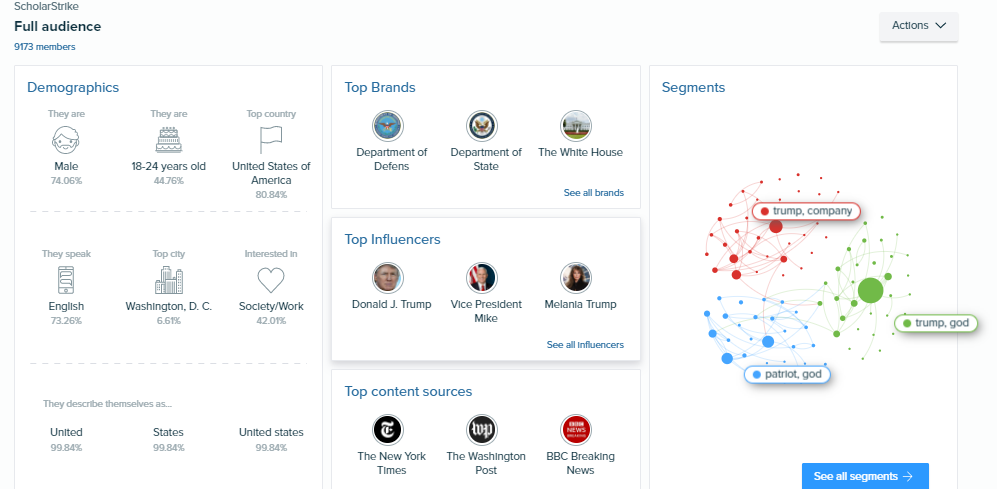
Figura 1. Informe de Audiense sobre #ScholarStrike.
Brand24, por el contrario, arrojó los datos de una forma más neutral. Como decíamos, a la búsqueda, que automáticamente al finalizar envía un email al administrador del proyecto, le sigue la posibilidad de descarga de un informe. No se puede trabajar sobre los datos. Se cree en los datos y las infografías o se los descarta.
Veamos, a continuación, qué narrativa nos ofrece esta última plataforma para la búsqueda #ScholarStrike.
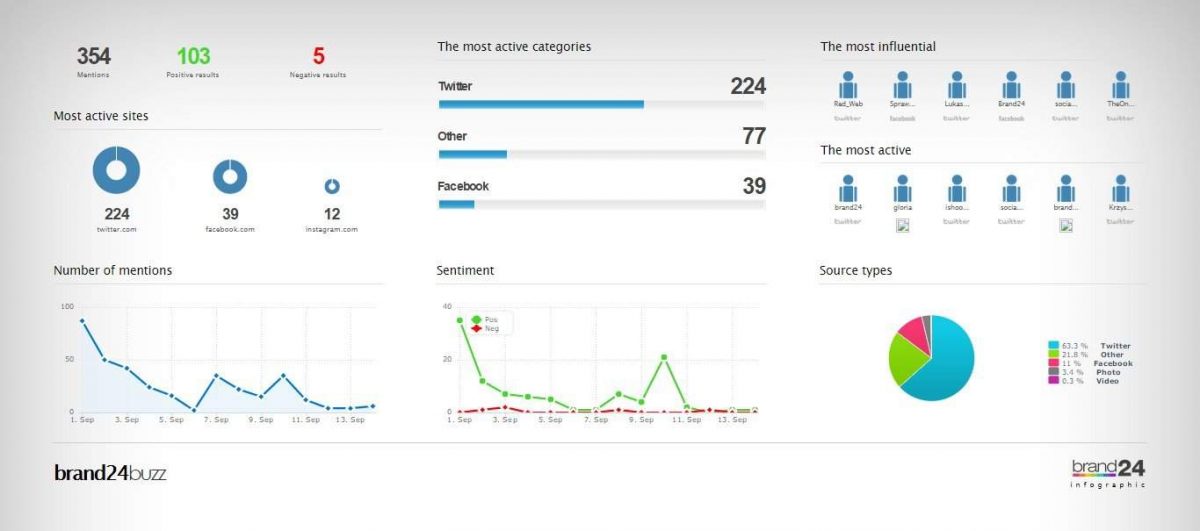
La primera búsqueda del hashtag la hicimos el día 13 y Brand24 realizó la búsqueda retrospectiva en los últimos 30 días (14 Aug 2020 – 13 Sep 2020). A las 24 horas, nos permitió la descarga de un informe y una infografía. En el primero, podemos ver que, en términos generales, el sentimiento acerca de la huelga fue positivo (44 positivos contra 21 negativos):

Figura 2. Resumen de las menciones de #ScholarStrike en redes sociales en Brand24.
Evidentemente, al ser solo una huelga de días, las menciones solo se producen en ese periodo, pero es notable cómo crecen al tercer día de comenzada la misma:
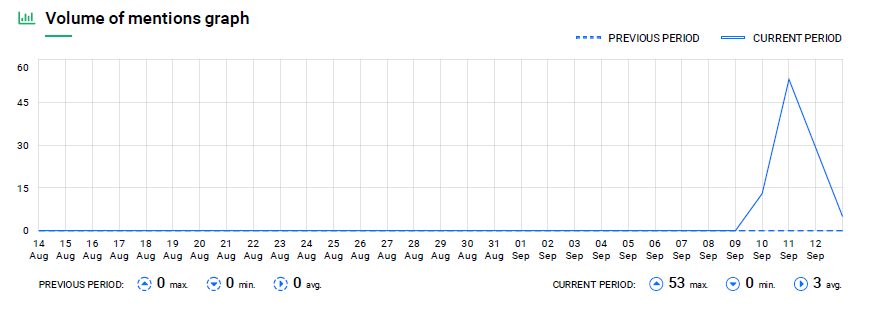
Figura 3. Gráfico de volumen de menciones de #ScholarStrike en redes sociales a lo largo del mes de septiembre.
Luego, la plataforma nos arroja una visualización de los términos más destacados de todas las redes sociales.

Figura 4. Conjunto de términos más nombrados en redes sociales dentro del contexto de discusión de #ScholarStrike.
Con justa razón, professor, teaching, son términos clave, ya que la huelga se dio en ese ámbito, pero, como decíamos en un principio, el entrelazamiento con el movimiento Black Lives Matter es visible el términos como racial, issues, september, police, injustice, black.
Es interesante, aunque esperable, dado su uso político, que de las dos redes sociales más populares, Facebook y Twitter, es la segunda la que se destaca. Otro término destacado es Butler. Lo interesante aqui es que, fuera de contexto, Butler podria asociarse a la filósofa y teórica Judith Butler, quien ha tenido una intervención activa en el movimiento BLM, a través de publicaciones en periódicos, y en redes sociales, y ha sido muy citada a partir de su tesis de la performatividad del género, tal y como lo muestran estas publicaciones: https://opinionator.blogs.nytimes.com/2015/01/12/whats-wrong-with-all-lives-matter/ o
https://iai.tv/articles/speaking-the-change-we-seek-judith-butler-performative-self-auid-1580. Sin embargo, este término hace referencia a Aethna Butler, profesora en estudios religiosos y estudios africanos y afro-americanos de la Universidad de Pensilvania, quien fue una de las organizadoras del Scholar Strike: https://www.insightintodiversity.com/professors-lead-a-nationwide-scholar-strike-for-racial-justice/
A continuación, la plataforma nos muestra los usuarios más activos y los más recientes en cuanto a su actividad en Twitter:

Figura 5. Menciones más populares y más recientes en Twitter con sus usuarios.
Resulta difícil saber si la herramienta está midiendo a los más populares por cantidad de Tweets o por retweets. Por lo que se ve en las imágenes siguientes, parece que la medición se hace a partir de las menciones y estas son las que miden el grado de influencia de un usuario en Twitter (figs 6 y 7).
No obstante, lo que más nos llama la atención es el usuario ISASaxonists, un grupo de medievalistas especialistas en lit medieval anglosajona (fig 5).
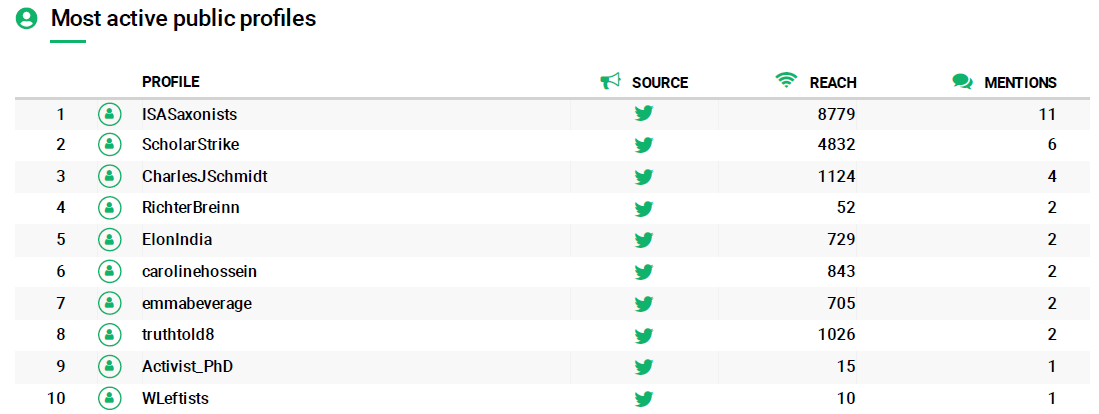
Figura 6. Perfiles públicos más activos en Twitter relacionados con #ScholarStrike.
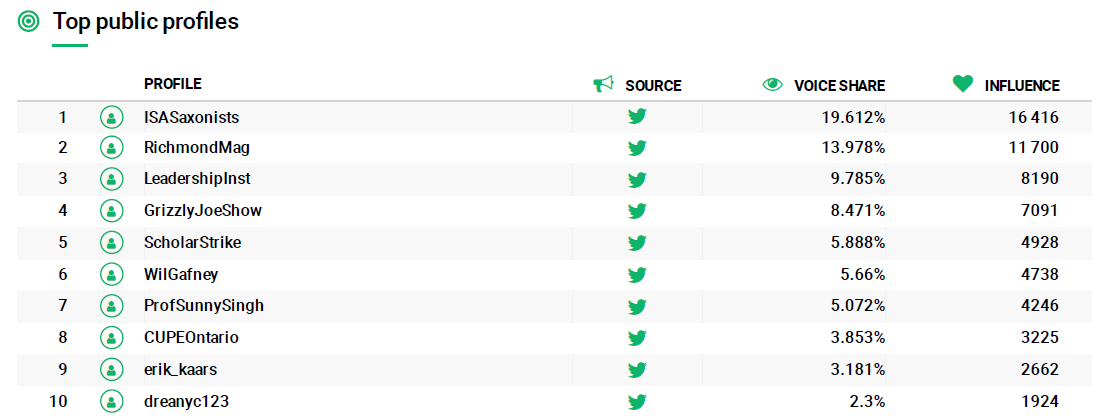
Figura 7. Perfiles públicos más influyentes en Twitter.
En último lugar la plataforma muestra los hashtags más usados (y relacionados entre sí):
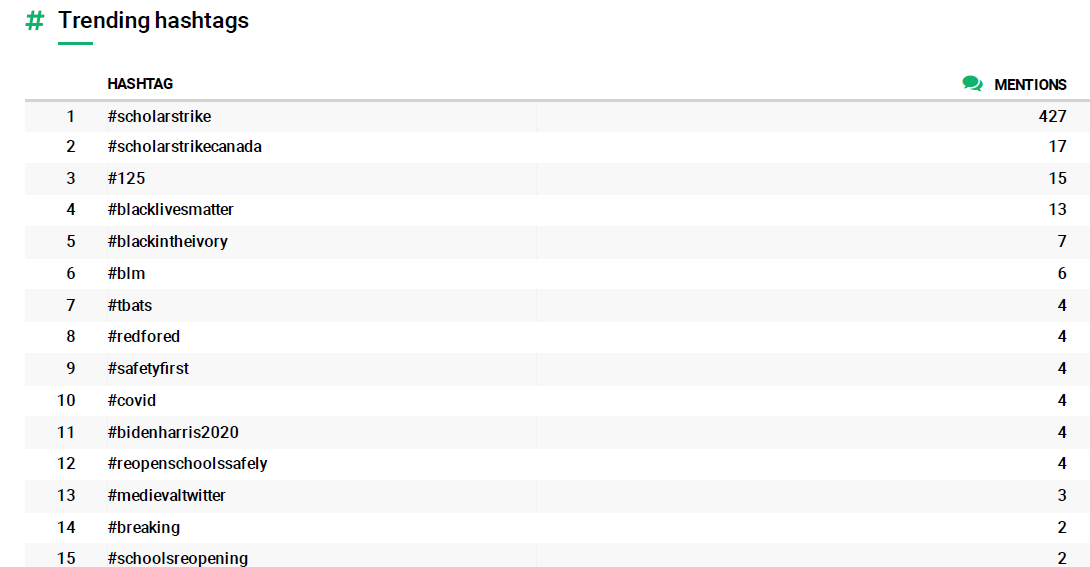
Figura 8. Hashtags más mencionados en Twitter, a partir de la búsqueda #ScholarStrike.
#ScholarStrike, #BlackLivesMatter, #covid son hashtags esperables. Una vez más, lo interesante aquí es el hashtag medievaltwitter, en 13 lugar, que, aunque la plataforma no lo explicita, debe estar relacionado, por ejemplo, con usuario ISASaxonists. De ser el caso, sería interesante pensar si tanto el hashtag medievaltwitter como los tweets del usuario ISASaxonists están relacionados con las acusaciones que ocurrieron en 2019 a la Sociedad Internacional Anglo-Sajona por su inhabilidad de dar cuenta de problemas de racismo, sexismo, diversidad e inclusión dentro de la misma. Parte de esta discusión fue publicada en revistas académicas en Estados Unidos durante septiembre de 2019:
En conclusión, explorar el contexto de #ScholarStrike con la plataform Brand24 nos permitió constatar algunas suposiciones previas (su relación con hashtags como BLM, Covid) pero iluminó otros hashtags menos esperables para un usuario no académico, como #medievaltwitter, y otros que aparecían tímidamente, pero pronto comenzaron a tener más impacto semanas siguientes, con la carrera electoral, como #bidenharris2020.
Gimena del Rio / Marisol Fila


