
In this post, we will present another way to explore our dataset of tweets on Covid-19. We intend to detect emerging topics of interest for our study of the social narratives about the pandemic. For this, we will perform unsupervised machine learning using different Python libraries.
In this case, we work with data in Spanish, but the same processing can be applied to English data; only a few parameters will diverge.
“Cleaning is usually 80% of a data scientist’s time”
Working with big data usually involves spending most of the time cleaning and organizing the data (source). This case is no exception! Cleaning is crucial for text processing not only because it reduces a text making it easier to read by machine, but also because it can significantly improve the quality of the results.
Our first step is to filter stopwords and emojis. We used generic lists available in standard libraries (NLTK, emoji). Based on the results, we refresh the list of stopwords to eliminate noise (e.g., “retwitt”) or words that are too obvious (e.g., “covid19”).
Another important step of preprocessing is part of speech detection and lemmatization. We chose to use Stanza (from Stanford NLP) because it yields better results for Spanish lemmatization. Spacy could be a better choice for English, since it obtains good results with reduced morphology languages such as English. The processing time is also notably faster than with Stanza.
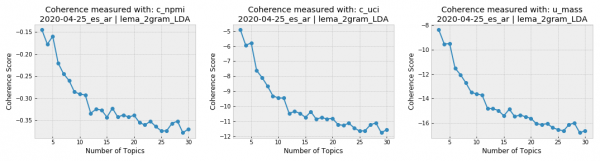
After preprocessing, we can tackle detection of the main topics of our Covid-19 corpus with machine learning using Gensim, a Python library for topic modeling. We will perform an unsupervised learning because we don’t know the content or quantity of our topics in advance. Then, we will train our models with LDA for 3 to 30 topics.
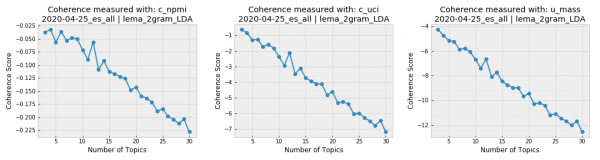
The topic coherence plots generated for the Spanish-language tweets from April 25th show that the conversation in our Covid-19 corpus was very focused, since the coherence drastically falls when the topic number grows. Given the opposite case (when topic coherence scores better for more topics), it is important to find an agreement between the results of the coherence scores and the number of topics interpretable by humans. It is hard to imagine a human analysis dealing with over a dozen topics for the same corpus.
Visualizing the results with graphics is very helpful for the analysis. A popular library for visualizing topic models is pyLDAvis, which shows the most frequent words of each topic in an interactive graphic.
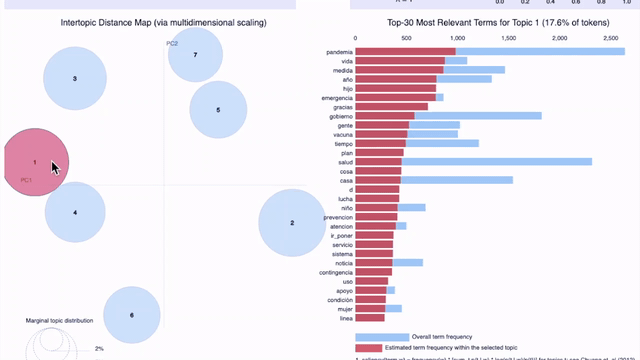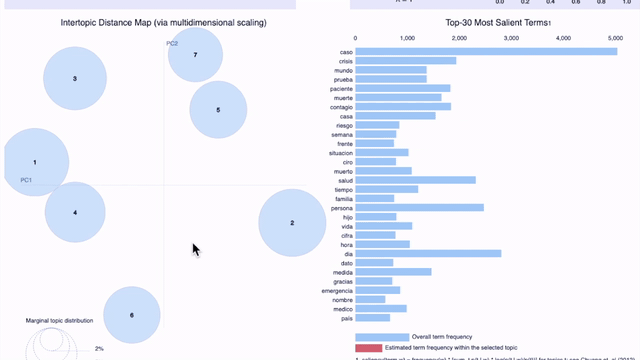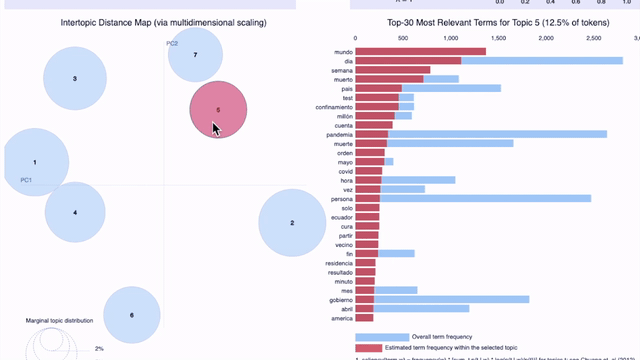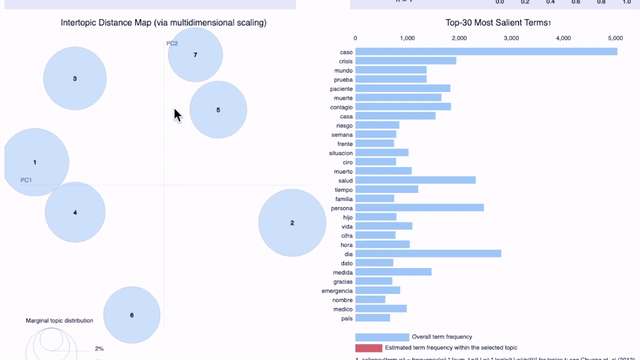
On the previous graphic, which shows seven topics for tweets from April 25th in all the locations of our sample (Argentina, Colombia, Ecuador, España, Florida, México, and Perú), we can observe the problem pointed out earlier: it becomes difficult for a human to understand the criteria used to group certain words under a certain topic. As the topic number increases, the topics are less interpretable, even if they have high coherence scores.
This problem is probably due to the size of our sample: aside from Covid-19, Twitter users of each Spanish-speaking location discuss different, largely unrelated subjects. We will compare the results for Argentina and Colombia to find out.
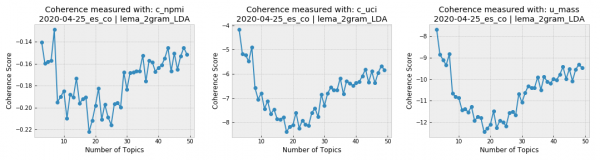
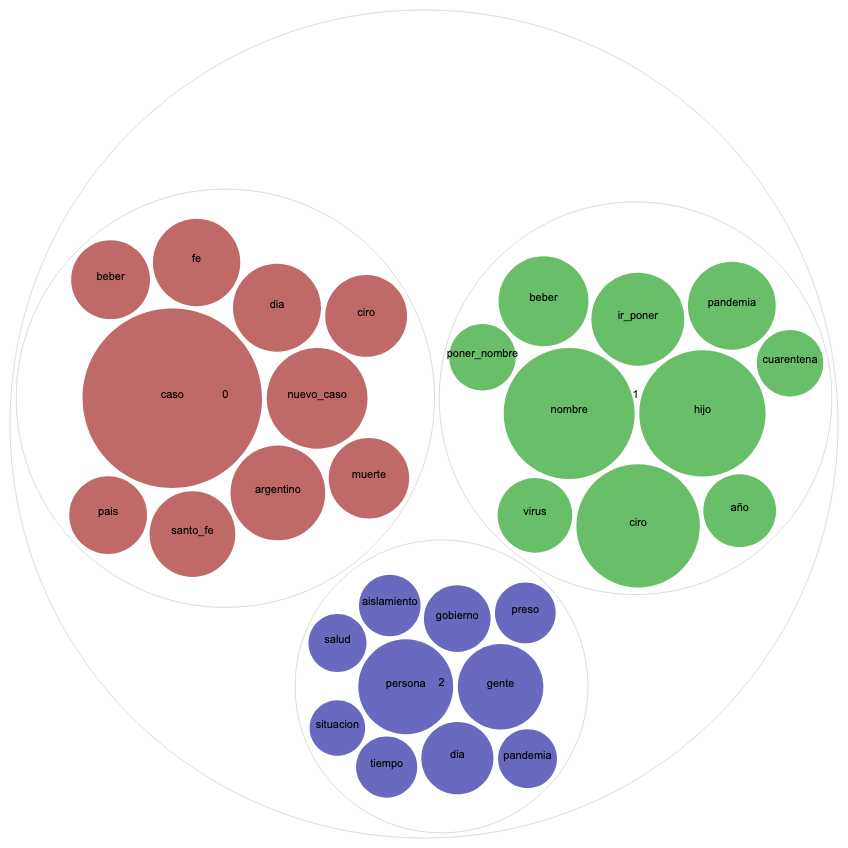
But first, a word on another type of visualization that we found very useful for topic modeling, Circle Pack. This type of graphic uses colors to represent different topics and spheres whose size is relative to word frequency. Let’s compare the Circle Pack for April 25th in Argentina and Colombia for three topics, given that both countries received high scores for this topic number.
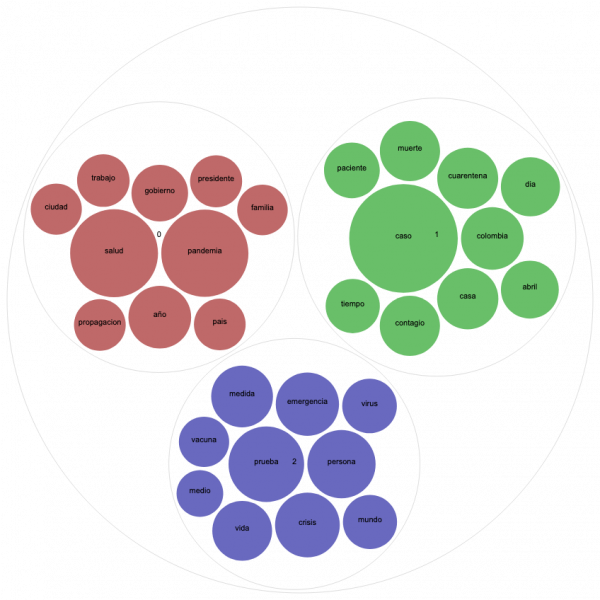
On the graphic for Colombia, the red circles represent a topic relating the pandemic to politics. It includes words as “government,” “president,” and “country”. The blue topic addresses public health issues, which includes “vaccine,” “virus,” and “test.” The green topic seems more related to daily statistics of case numbers, deaths, and infected people.
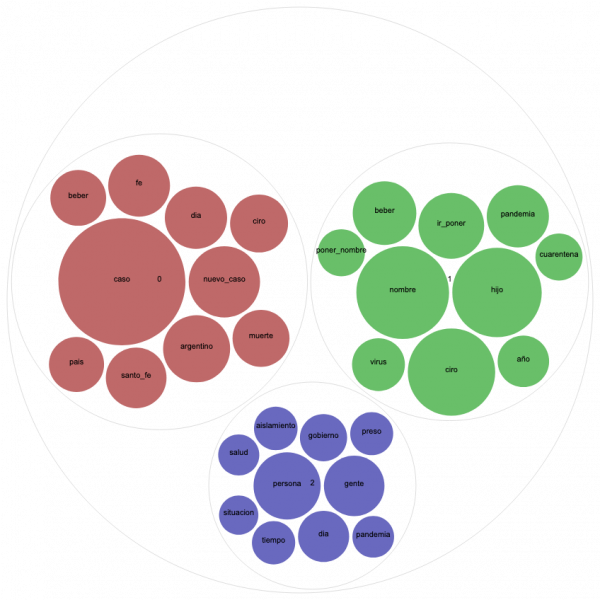
In order to interpret the Circle Pack for Argentina, it is essential to dive into the latest news of that particular day. Doing so reveals controversy surrounding a baby named Ciro Covid who was born on April 24th in Santa Fé, The question “Who would name her/his baby Ciro Covid?” that flooded Argentinian Twitter the next day is not only clearly represented on the green topic but also invaded the tweets of daily reports of case and death numbers (red topic). With a remarkably smaller dimension, we can observe another trending topic in Argentina that day: the controversy of inmates leaving on probation as a preventative measure, represented in blue.
Once again, we confirm that the humanist approach of understanding data and its contexts is critical for assigning a meaning to the results of automatic processing.
For more details about the processing performed for topic modeling, download the notebook available on our project Github repository.