
Coveet.py is a collection of Python scripts created by Jerry Bonnell, a PhD Candidate in Computer Science at the University of Miami, specifically for this project. The main features Coveet can perform are frequency analysis, sentiment analysis (currently improving), and concordance analysis.
Coveet fulfills three principal tasks.
(1) Querying Twitter data from the project API based on the criteria country, language, and date. Using the pandas package in Python, Coveet organizes the results into a data frame where each row contains a tweet and each column its corresponding metadata: date, language, country, body text, and hashtags. The output format is a CSV file, which can be inspected using spreadsheet software or used as input to another script.
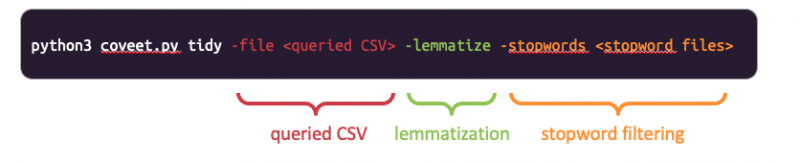
(2) Tidying queried data, e.g. by lemmatization and elimination of stopwords, to render it suitable for downstream textual analysis tasks. Each tidying step can be toggled depending on the needs of the analysis. Upon completion, the tidied body text and hashtags are written out to a new CSV file.
(3) Analyzing tidied data by application of NLP techniques: (1) frequent n-grams, and (2) unique word retrieval by location-language pair and dates, and (3) sentiment analysis.
To conduct n-gram analysis, a dictionary of location-language pairs is generated where each key is a location-language pair and the value a list of top n-grams under that setting, e.g. counts[(‘fl’, ‘es’)] would return the results for Spanish tweets written in the Miami area. Therefore, the location-language pairing uniquely identifies a region of interest with a target language. We reinterpret the full tweet as context, not only adjacent neighbors, to allow for the possibility of more results. In the case of bigrams (n = 2), this means considering the occurrence of two words in a tweet, regardless of whether they are adjacent, as a bigram candidate. Once gathered, the most frequent n-grams can be computed where the number of top results to return can be adjusted. From frequent words (n=1) to frequent phrases (n > 1), frequency analysis can return different results leading to new findings.
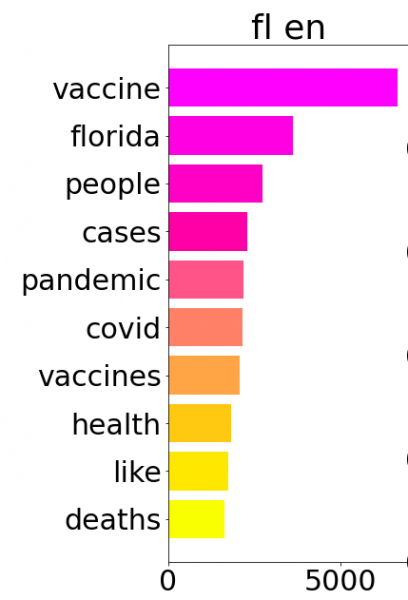
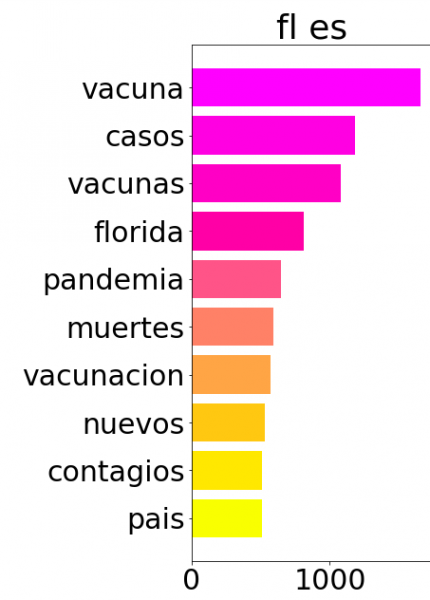
The “unique words” mode assists researchers to quickly identify distinct characteristics, rather by location, time, or language. The basis of comparison, thus, is essential in building this function. Coveet constructs a unique “vocabulary” dictionary for each location-language pair where the words that appear in that group are mutually exclusive from all other pairs available in the data frame. Similar to stopword elimination, this construct is used to filter out any words from tweets that are not present in the dictionary.
Each component is built independently so that the incorporation of new techniques can be done with minimal effort. This is key if new interpretative demands are to be met, and if the tool is to be used in future studies.
In a separate sentiment analysis Jupyter notebook file, you may explore the emotional patterns. Jerry has written a detailed step-by-step instruction in the .ipynb file.
You may find an example that demonstrates Coveet in investigating our corpus in Frequency Analysis for South Florida (April – June).