
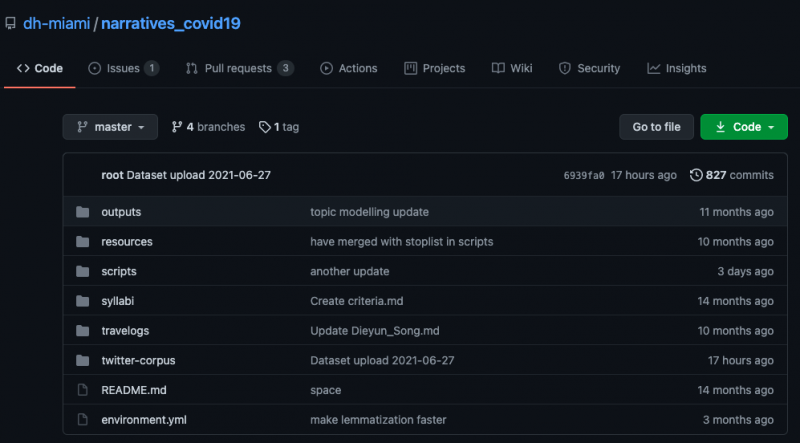
Thank you for exploring our code and resources in our GitHub Repository, where you may access our corpus, scripts, administrative logistics, and collectively gathered resources in one place.
The “twitter-corpus” folder contains our entire dataset starting on April 24, 2020 organized by day. You may then see .txt files sorted by language-location pairs.
You may access our Python scripts for frequency analysis, sentiment analysis, topic modeling, and stopword tidying in the “scripts” folder, and view some preliminary results in “outputs.”
Where did all the data come from?
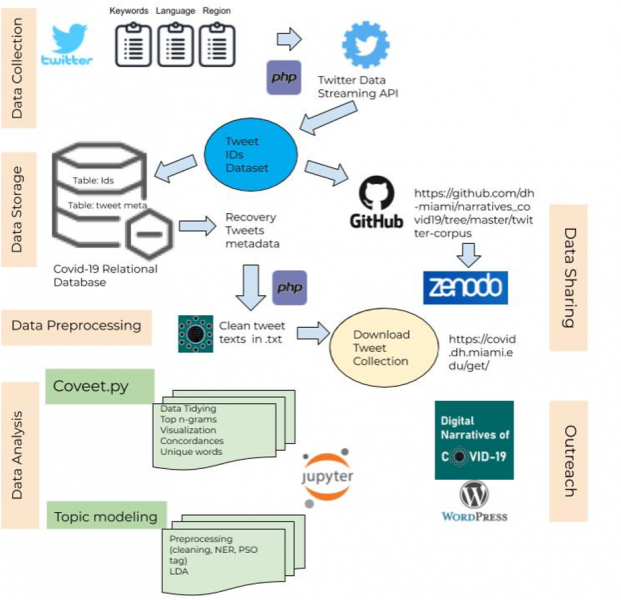
First, to assemble the Twitter corpus (data collection), a PHP script mines the Twitter Data Streaming through Twitter’s Application Programming Interface (API) and recovers a series of specific tweet IDs. Our data mining sampling strategy consists of four main variables: language, keywords, region, and date.
Then, Tweet IDs are stored in a MySQL relational database where they are “hydrated,” that is, all metadata associated with the tweets is recovered, including its body text.
Third, an additional script organizes the tweet IDs in the database by day, language, and region, and creates a plaintext file for each combination with a list of corresponding tweet IDs. The script generates these files daily and organizes them into folders, where each directory represents one day. These are uploaded directly to our public GitHub repository, where we provide free access to these datasets.
One the tweets IDs are recovered and introduced into the database, we proceed to the data processing phase, where we standardize the data by rendering everything in lowercase, removing accents, punctuations, mention of users (@users) to protect privacy, and replacing all links with “URL.” This step is especially challenging and, yet, crucial considering the frequent use of accents and graphemes in Spanish (like the ñ). Emojis are a tricky challenge as some of them could be transliterated into a UTF-8 charset and be transformed into emoji labels, while others are not recognized and remain in the text. Additionally, we decided to unify all different spellings of Covid-19 under a unique form, and all other characteristics, including hashtags, are always preserved. This step allows us to obtain a clean and tidy collection of tweets organized by language, by day, and by area, and to respond to our research purposes.