
En este post, presentaremos otra manera de explorar nuestro dataset de tweets sobre el Covid-19 con el objetivo de detectar temas o tópicos emergentes de interés para nuestro estudio de las narrativas sociales acerca de la pandemia. Para ello, realizamos un procesamiento de aprendizaje automático no supervisado con la ayuda de diferentes librerías para Python.
En este caso, trabajamos con material en español pero el mismo procesamiento puede aplicarse al corpus en inglés, con algunas diferencias en los parámetros de lengua.
“Preparar datos es 80% del trabajo de data science”
Ya es sabido (ver fuente) que cuando se trabaja con grandes corpus, la mayor parte del tiempo se dedica a limpiar y organizar los datos. ¡Y nuestro caso no es la excepción! Esta tarea es muy importante ya que no sólo reduce el volumen de los datos facilitando su procesamiento automático, sino que también tiene una enorme influencia en la calidad de los resultados.
En primer lugar, filtramos las stopwords y los emojis. Usamos listas genéricas disponibles en librerías standard (NLTK, emoji) que actualizamos continuamente con ítems específicos de nuestro corpus en base a los resultados obtenidos (‘retwitt’, ‘covid19’, etc.).
Otro paso importante del preprocesamiento es la detección de categorías (Part of Speech) y la lematización. Usamos Stanza (de Stanford NLP) porque da mejores resultados para tratar la morfología del español. En inglés, cuya morfología flexiva es más reducida, es posible usar Spacy con buenos resultados y un tiempo de procesamiento mucho menor.
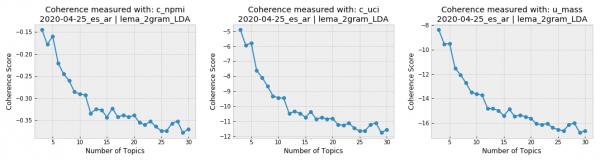
Una vez que terminamos el preprocesamiento, podemos detectar automáticamente los tópicos predominantes en nuestro corpus con aprendizaje automático gracias a Gensim, una librería de Python para topic modelling. Realizamos un aprendizaje no surpervisado porque no tenemos manera de saber de antemano cuáles son los tópicos ni cuántos son. Entrenamos modelos con el algoritmo LDA para 3 a 30 tópicos.
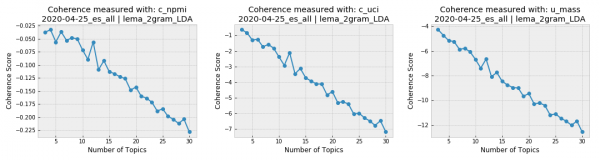
Los gráficos de coherencia de los tópicos generados para todos los tweets en español del 25 de abril nos muestran que la conversación en nuestro corpus de coronavirus se encuentra muy concentrada, ya que la coherencia disminuye marcadamente a medida que el número de tópicos aumenta. Si se diera el caso contrario (mayor índice de coherencia al aumentar el número de tópicos) sería importante encontrar un compromiso entre los resultados de los scores de coherencia y un número de tópicos al alcance de la interpretación humana, ya que resulta difícil imaginar un análisis humano que maneje más de una docena de tópicos para el mismo corpus.
La visualización de los resultados en gráficos es de gran ayuda para facilitar el análisis. Una forma de graficar los tópicos es usando pyLDAvis, una librería para visualizar de manera interactiva las palabras que conforman los tópicos configurados por los modelos.
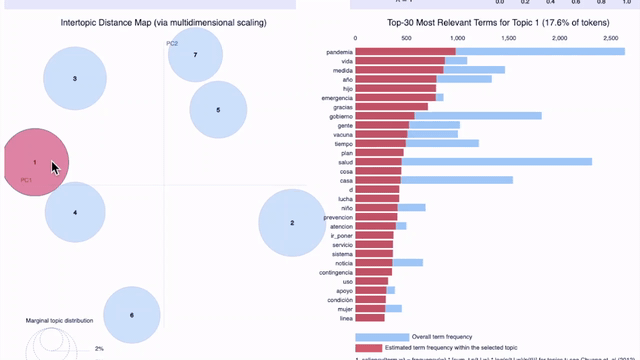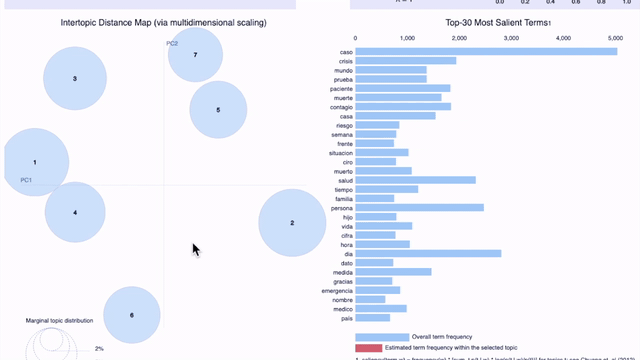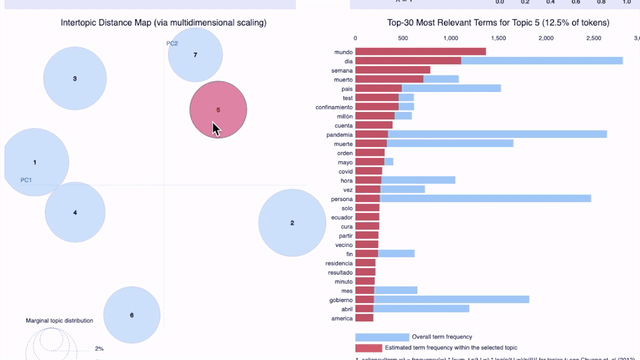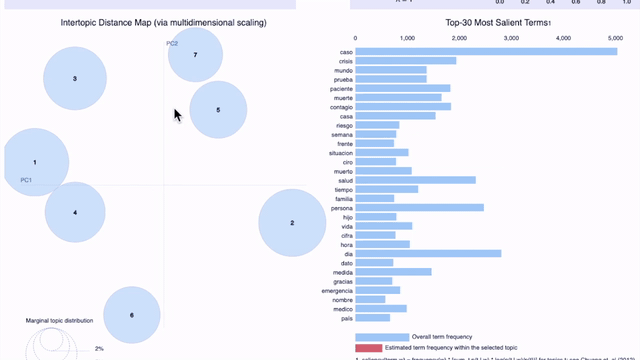
En el gráfico precedente (click aquí para abrir el gráfico en una pestaña nueva) en el que se grafican 7 tópicos para el 25 de abril para los tweets en español en todos los países/regiones de nuestra muestra (Argentina, Colombia, Ecuador, España, Florida, México, Perú), podemos observar lo que señalamos más arriba: es difícil para un humano encontrar el criterio por el cual fueron agrupadas ciertas palabras como parte del mismo tópico. A medida que aumenta el número de tópicos, éstos se vuelven menos interpretables aunque tengan alto score de coherencia.
Probablemente, esto se deba a la amplitud de nuestra muestra: más allá del covid19, los usuarios de Twitter de cada país deben abordar diferentes temáticas que poco tienen que ver. Comparemos los resultados para Argentina y Colombia, por ejemplo.
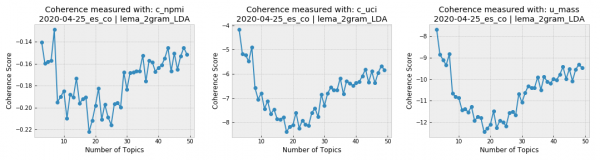
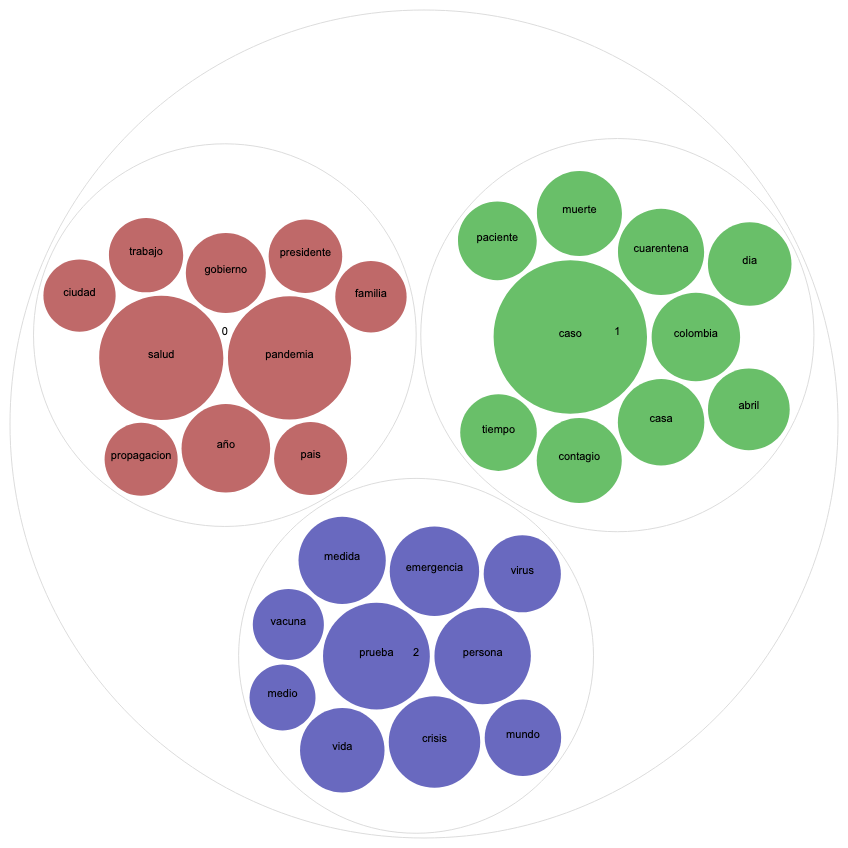
Otro tipo de visualización útil para el topic modelling es el gráfico de Circle Pack, donde los colores representan los diferentes tópicos y el tamaño de las esferas la frecuencia de las palabras. Vamos a comparar el Circle Pack del 25 de abril de Argentina y Colombia para 3 tópicos porque ambos recibieron un score alto de coherencia para ese número.
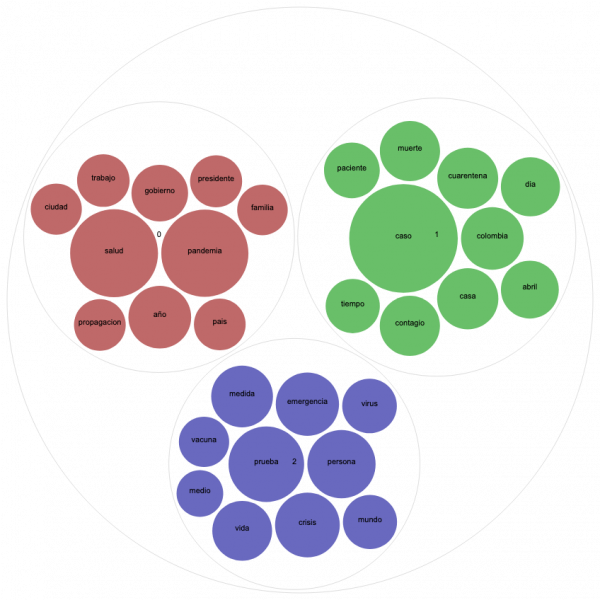
En el gráfico de Colombia, vemos un tópico (color rojo teja) que relaciona la pandemia con la política, que incluye palabras como “gobierno”, “presidente”, “país”; otro tópico (color azul) que aborda cuestiones más vinculadas a lo sanitario, que incluye “vacuna”, “virus”, “prueba” y otro tópico (color verde) que parece más vinculado a las estadísticas diarias de números de casos, muertos y contagiados.
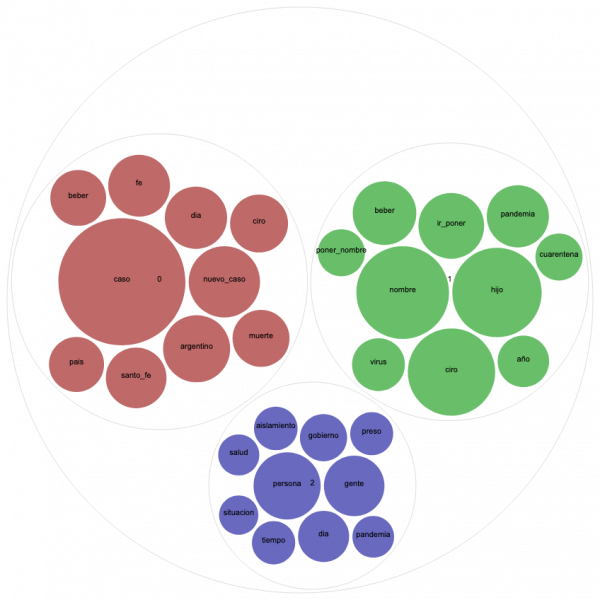
Para interpretar el Circle Pack de Argentina, es imprescindible conocer el tema de actualidad de ese día particular (ver noticia): un bebé de la ciudad de Santa Fé que fue nombrado Ciro Covid el 24 de abril. La pregunta “¿Quién va a ponerle de nombre a su bebé Ciro Covid?” que predominó en Twitter Argentina al día siguiente, no sólo está representada claramente en el tópico verde, sino que invadió también los tweets con partes diarios de números de nuevos casos y fallecidos (tópico color rojo teja). En una medida mucho menor, otro tema abordado ese día en ese país, fue la polémica sobre otorgar libertad condicional a presos como medida de prevención, representado por el color azul.
Una vez más, confirmamos que el aporte de una mirada humanista interesada en el conocimiento de los datos y su contextualización es de gran ayuda para asignar significados a los resultados del procesamiento automático.
Para más detalles sobre el procesamiento realizado para obtener los tópicos, descargue la notebook disponible en el repositorio de GitHub del proyecto.