
Nidia Hernandez, a researcher at CONICET based in Argentina, created our topic modeling script in Python. Topic modeling is a natural language processing (NLP) technique and one of the most effective distant reading methods to understand, characterize a large-scale corpus that is beyond human capacity. Researchers can use this method to investigate the main events, locations, individuals, and the perceived evolutions of the pandemic appearing in the corpus.
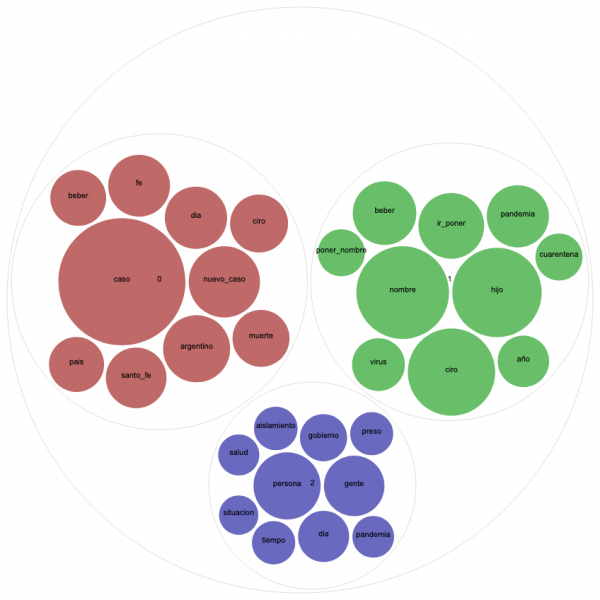
We use a bag-of-words approach combined with bigrams that only contains tweet text without the metadata or the links. Starting with data processing, we first remove stopwords, numbers, and any remaining emojis, then proceed with named entities recognition, speech tagging, and lemmatization.
When dealing with highly inflected languages such as Spanish, lemmatization not only optimizes the automatic processing by reducing the size of the data, but also by equalizing items with the same lexical information. We decided to only keep named entities and nouns since those are the items that hold the most substantive significance considering our texts. For phrases, such as “nuevo caso” (new case) and “flexibilizar cuarentena” (relax quarantine), which include more than nouns, we design the script to generate bigrams of each tweet and include the most relevant bigrams to the input data for the topic modeling before filtering by part of speech. After this preprocessing, the data was processed with Latent Dirichlet Allocation algorithm using Gensim, an open-source and accesible Python library for topic modeling.
Please see “Outbreak Topics: Topic modeling of COVID-19″ as an example of how to use the script to work with our data.