
Twitter public discourse is one of our project’s primary research concerns. Twitter’s rich data has also drawn more and more researchers from various disciplines and fields to explore different aspects of society. This blog post serves as a tutorial of using DocNow Hydrator to “hydrate” tweets. Our project, as we explained, is offering a series of datasets on Covid-19 that can be downloaded onfrom our GithHub repo.
Due to Twitter’s Developer terms and research ethics, most TweetSets we can acquire from Twitter’s Application Programming Interface (API) and third-party databases are dehydrated tweets. In other words, instead of collecting tweet contents, geolocations, time, images, and other attached information to tweets, what researchers would initially receive is a plain text file consisting of a list of unique tweet IDs. These IDs allow us to retrieve all tweet metadata, including the text, and they need to be “hydrated” to recover the metadata and to become meaningful research sources. The large size of tweets’ correlated data is another reason why datasets offer only dehydrated IDs. Thus, a file containing only a series of numbers (IDs) is much manageable than, for example, a csv file with thousands of tweets with their metadata.
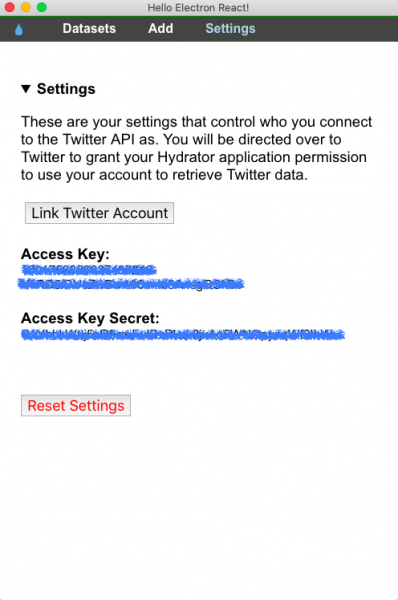
DocNow Hydrator is a commonly used open-source software to hydrate tweet IDs and can be downloaded for free on Github. You need to link to your Twitter account in “Settings” before using Hydrator.
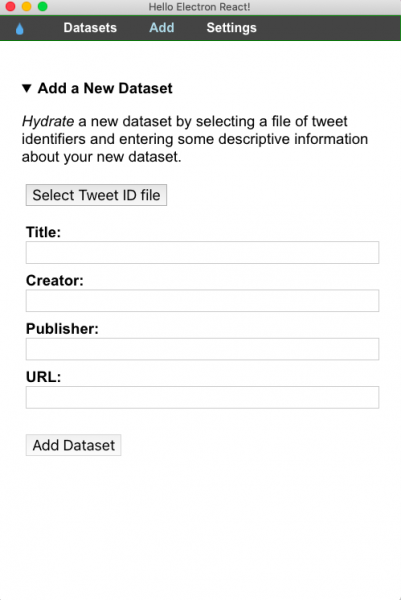
Once your Hydrator is set up, you can upload your tweet IDs file to Hydrator. In our case, we use the Covid-19 dataset from our Digital Narratives project’s GitHub repo, which we update on a daily basis:
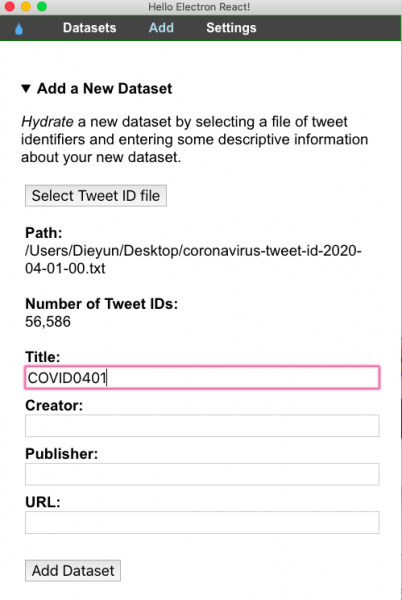
If your file has been processed correctly, Hydrator would display your file path and compute the total number of tweet IDs detected. In “Title” you can rename your hydrated file, while the rest of the boxes can be ignored. Then click “Add Dataset.”
Click “Start” to hydrate the tweet IDs.
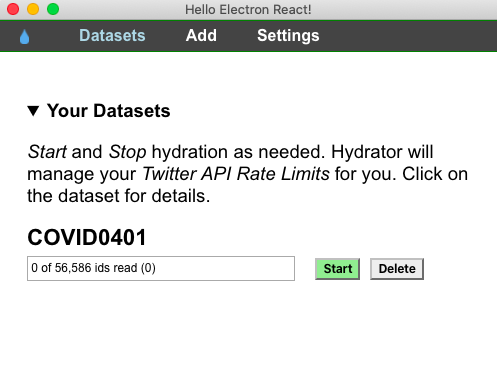
A new window would pop up and ask you to locate and name your hydrated tweet IDs file. Hydrator will generate a .json file by default. Making your document a .csv file makes it more easily assessable by Excel and other file readers.
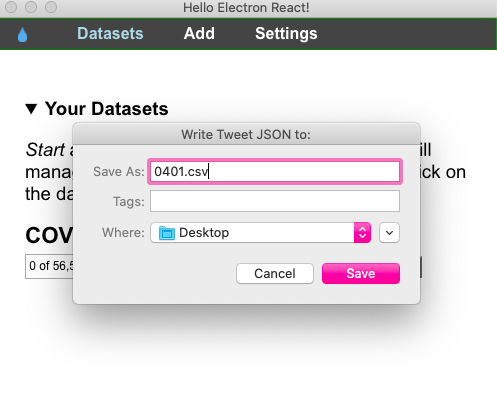
Hydrator will then begin the hydration process. Completion time depends on the number of tweet IDs.
The completed .csv file now displays all the correlated information of the original tweet IDs.
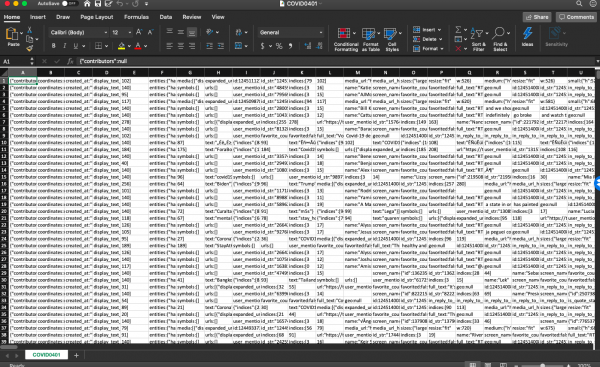
Researchers then can analyze geolocations, images, emoji’s, tweet discourse, hashtags, time, and other correlated information and metadata for various purposes. If you use our dataset, please keep us updated and please feel free to share your valuable feedback and suggestions with us. Stay tuned and thank you for keeping up with our project.