
This post compares the top 30 most frequent words and the top 20 hashtags in our Twitter English and Spanish corpora of South Florida from April 25th to June 25th, 2020. We divided it into 2 four-week periods to analyze broad trends and themes in the discourse.
For our corpus criteria as well as for the keywords used to harvest our corpus, please refer to our blog post “A Twitter Dataset for Digital Narratives“. As for our corpus, check our GitHub repo for the ID datasets to recover tweets collections.
The project uses Coveet, a frequency analysis tool in Python developed by Jerry Bonnell, a PhD student in Computer Science at the University of Miami, that retrieves basic statistics (most frequent words, bigrams, trigrams, top users, hashtags, etc.). Coveet allows 1) customized stopword removal, 2) top words retrieval by date, location, and language, 3) mining unique top words by location and date, 4) collocation analysis, and 5) visualization.
We have prepared a version of this post with a Jupyter notebook in our GitHub repo that is available to be run via Binder.
As far as the number of tweets concerns, these are the totals in the South Florida area by month. As we can see, tweets in English are much frequent than in Spanish:
| 25/April – 25/May | 25/May – 25/June | |
| Tweets in Florida in Spanish: | 6,695 | 4,957 |
| Tweets in Florida in English: | 23,548 | 18,867 |
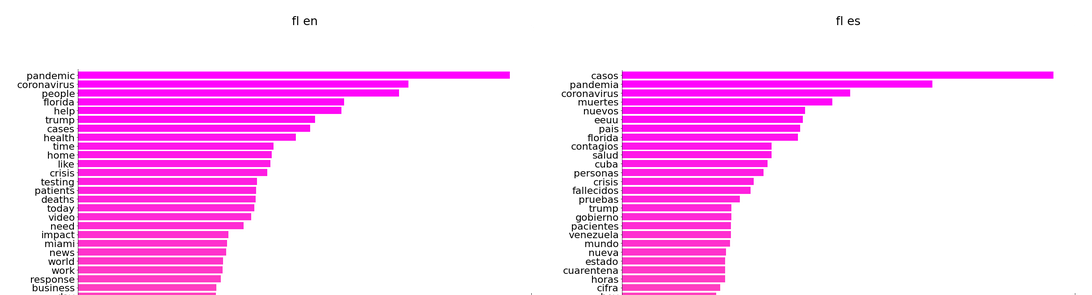
Top 30 words in South Florida from April 25th to May 25th: English vs Spanish
We will start this post by querying the tweets for the first four weeks from April 25 to May 25 in South Florida in both English and Spanish. We have prepared the dataset for interpretation, by removing stop words, which refers to the most common words in the language that appear so frequently that bear little significance. Removing stop words makes it easier to focus on the substantive discussions and themes in the corpus. There is not a standard list of stop words in each language. A few examples of stop words include “I,” “is,” “and,” etc. We have established our own list of stop words in our GitHub repo, for English and Spanish.
The process used for all periods is as follows: After the query is done [3], our coveet.py script, with the help of the pandas package, processes all commands in a csv file, which can be read via Excel and is downloadable and portable [4]. We then run a function consisting of tidying the csv data by removing the stopwords [5]. Afterward, we organize the resulting data by showing data, text, and hashtag, and to separate strings of texts into individual words (consequently a normal string such as “have a great days” is converted into “have” “a” “great” “day” [6] . We finally create the top ngrams and visualizations for each section [7].
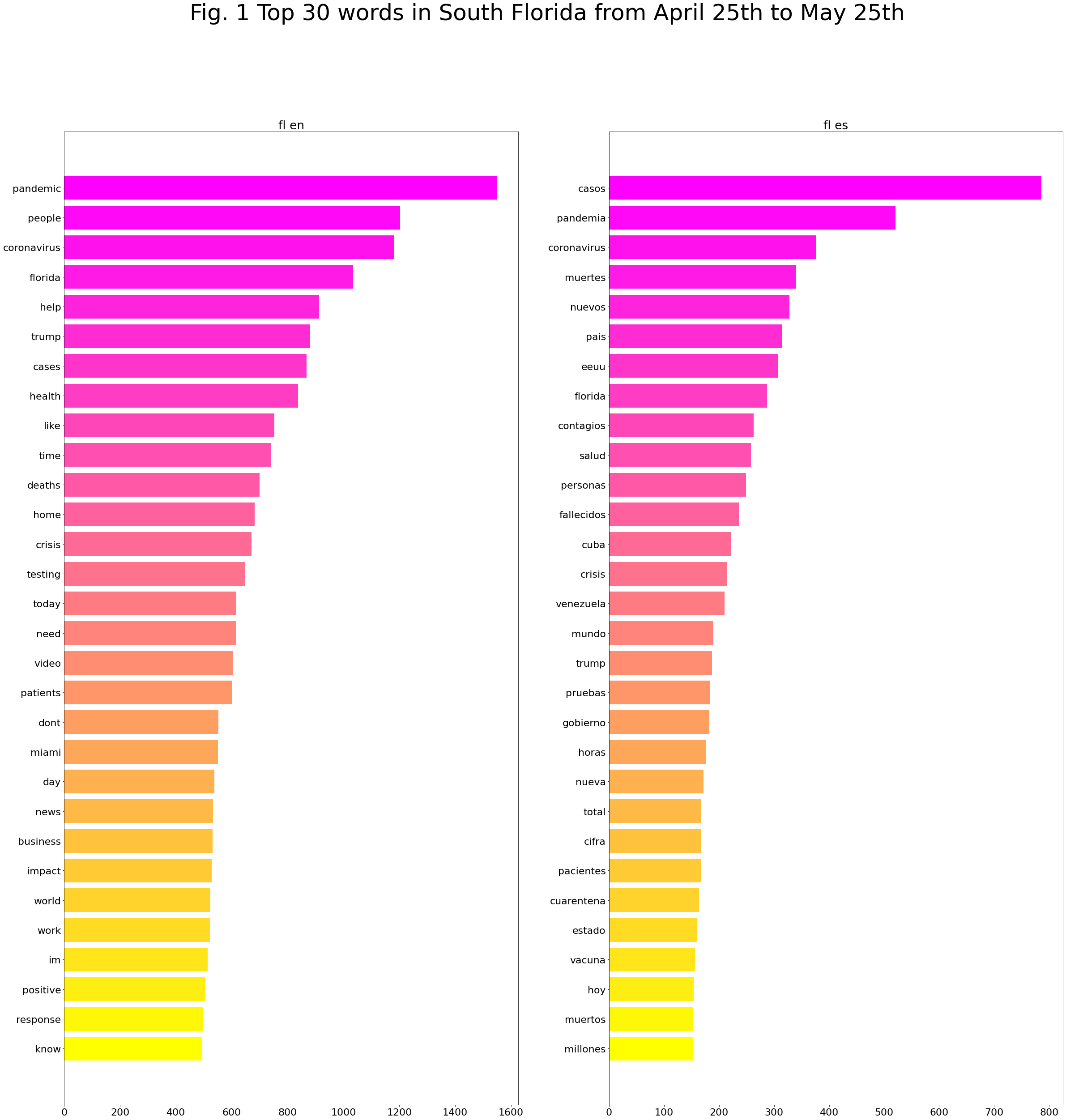
Top 20 hashtags South Florida from April 25th to May 25th: English vs Spanish
We have run the same process from April 25th to May 25th but recovering the 20 most used hashtags by language in South Florida.
English and Spanish discourses in South Florida both discuss daily new cases, infected patients, deaths, testing during this global crisis.
Comparing and contrasting the top words and hashtags points us to some interesting areas for further investigation.
- The Spanish discourse seems more global. “eeuu,” “Cuba,” “Venezuela,” and “pais” suggest that the Spanish corpus discussed the pandemic on a national and international scale. “Miami,” a local term, on the other hand, is unique to the English corpus, whose top words don’t include any country names. Here are a few important questions to investigate:
- Were foreign countries mentioned because of the large South Florida residents of Latin America, Cuba and Venezuela in particular, descent?
- Did these Twitter users want to compare the situation in the US to those of other countries?
- Why such international focus is more prominent in the Spanish corpus than the English corpus?
- Public health measures are more prominent in the Spanish corpus. “Cuarentena” and “vacuna” shows that the discussions of quarantine policies and vaccine take a significant weight in Spanish-languaged tweets, which neither is discussed in the English corpus. How shall we explain this distinction?
- The English corpus seems to be more “interactive.” “Help,” “need,” “support,” and “please” suggest a call for action from another individual, and are unique to the English corpus. These words imply that the English tweets have a stronger intention to interact with readers and influence others’ behaviors. With further concordance analysis, here are a few questions that come to mind
- To whom are these actions directed? Government agencies, the audience at large, hospitals, etc.?
- Are these demands for others, i.e. “people need to wear masks,” or calls for assistance for oneself, i.e. “my family needs support due to unemployment”?
- Which topical area did these words mostly appear in, economics, medical, political, personal, etc?
- “Business” and “work” are unique to the English corpus. Does it indicate more discussions about the economic effects of the pandemic?
- Since “gobierno” is unique to the Spanish corpus, how prominent is government-related discussions in Spanish tweets? Does the English corpus discuss government, at all? How do they differ?
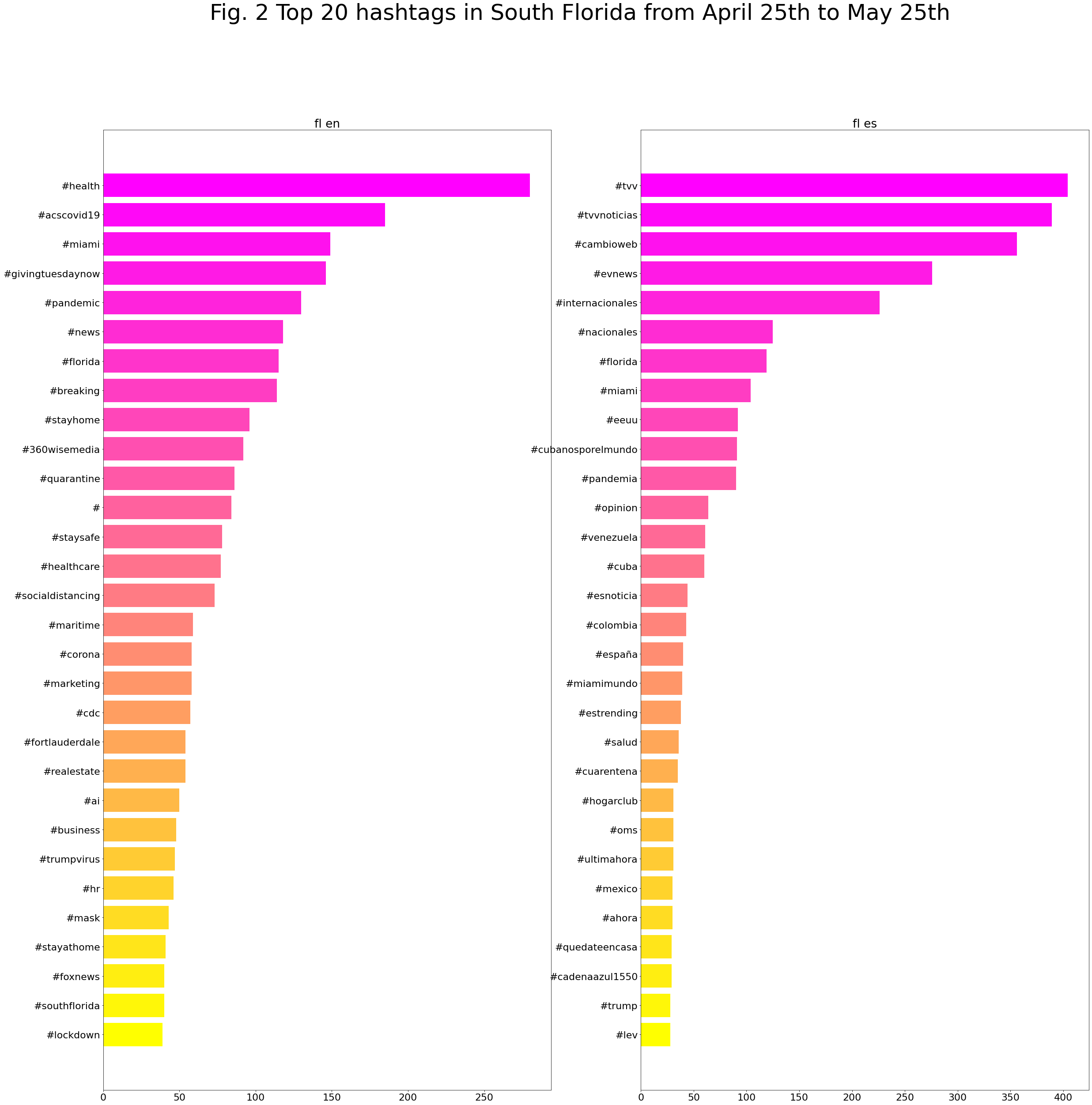
Top 30 words in South Florida from May 25th to June 25th: English vs Spanish
The same process now can be repeated for a second period, from May 25th to June 25th, and here are the top 30 words most used, after cleaning stopwords:
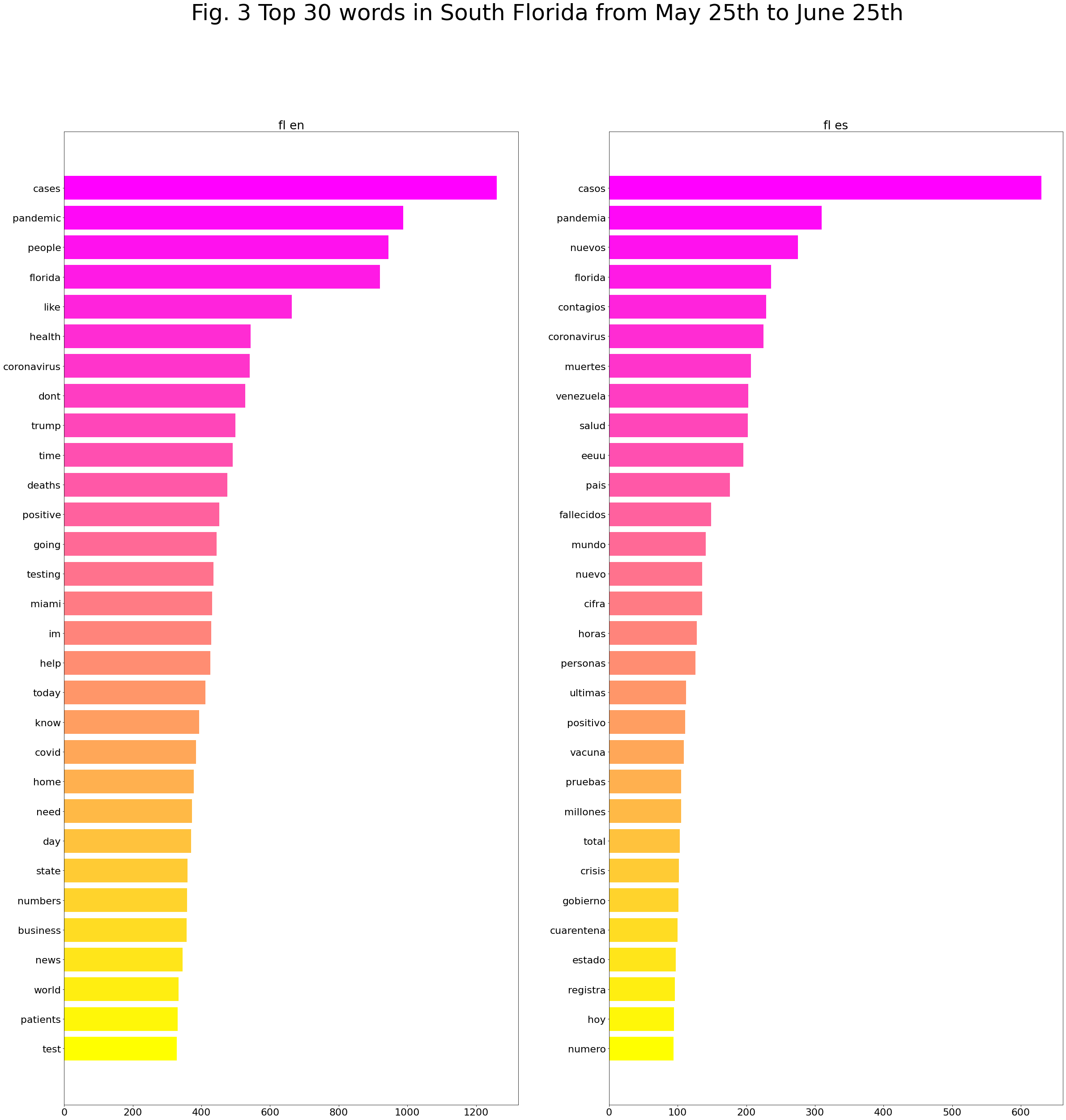
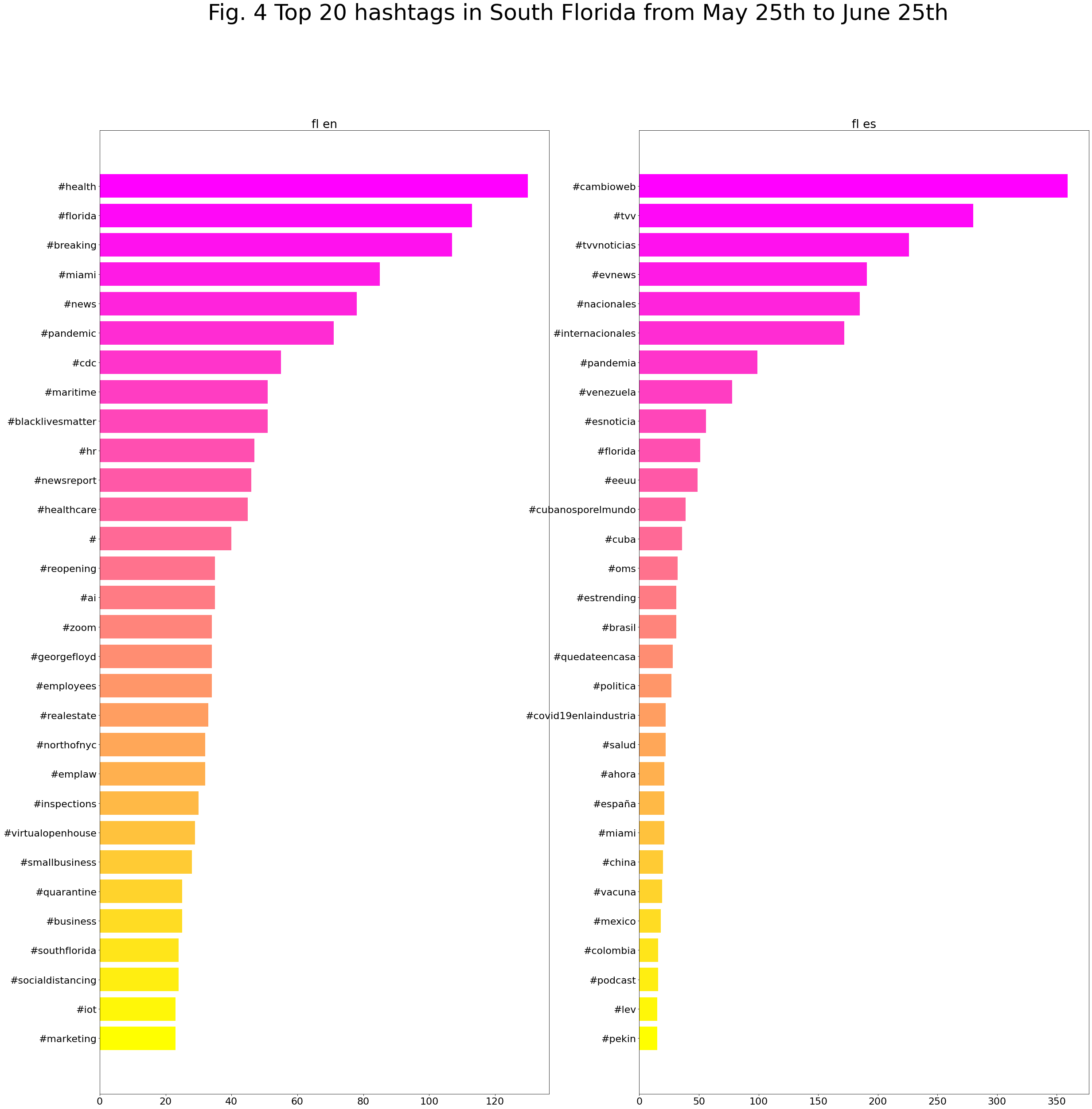
Top 20 hashtags South Florida from May 25th to June 25th: English vs Spanish
Also, here are a list of the most used hashtags in this period:
Let’s first look at the common top words. With cases/casos and new/nuevo rising to top two, we can speculate more discussions about the increasing number of cases in South Florida after late May. “Miami” shows up in both English and Spanish corpora, indicating more attention paid to this area by Spanish-language Twitter users.
The list of unique words further reveals some patterns and research questions.
- The Spanish corpus remains more “global.” Venezuela and Cuba are again hot topics among the Spanish-speaking population, but this time Venezuela appears first, with Brazil added to the list and China disappeared. As the situation of the countries worsen, they naturally rise to the upper position in the public conversations.
- “Masks” is (finally) a top word in the English corpus. This aligns with various states’ mandatory mask policies, calls for responsible protesting during the Black Lives Matter movement, and reflects an improved public awareness of responsible preventive measures.
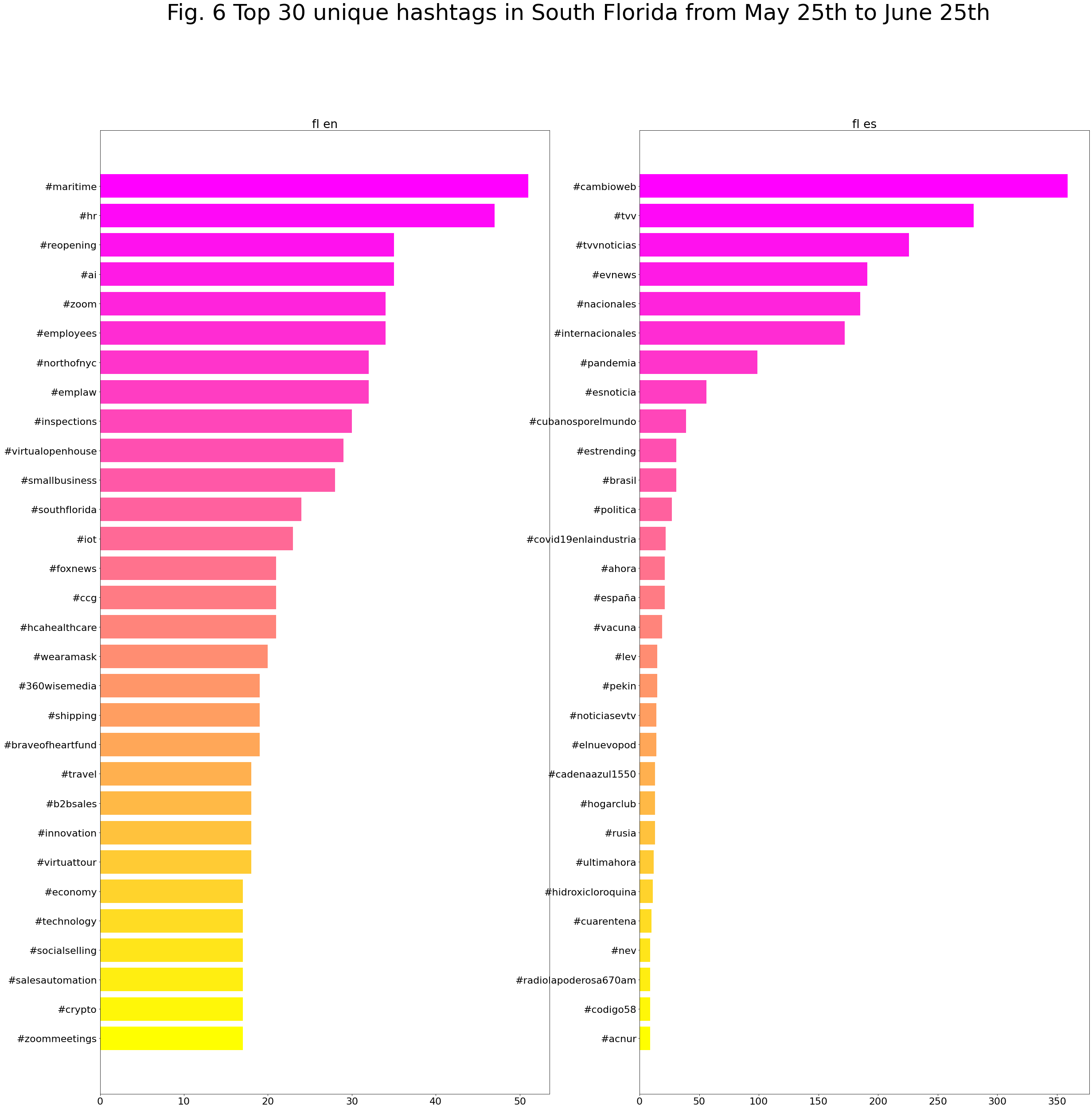
Top unique hashtags
It is also interesting to check the corpus looking only for unique hashtags that appear in English or in Spanish.
These are the top hashtags that appear in the fist period of time (April 25th to May 25th):
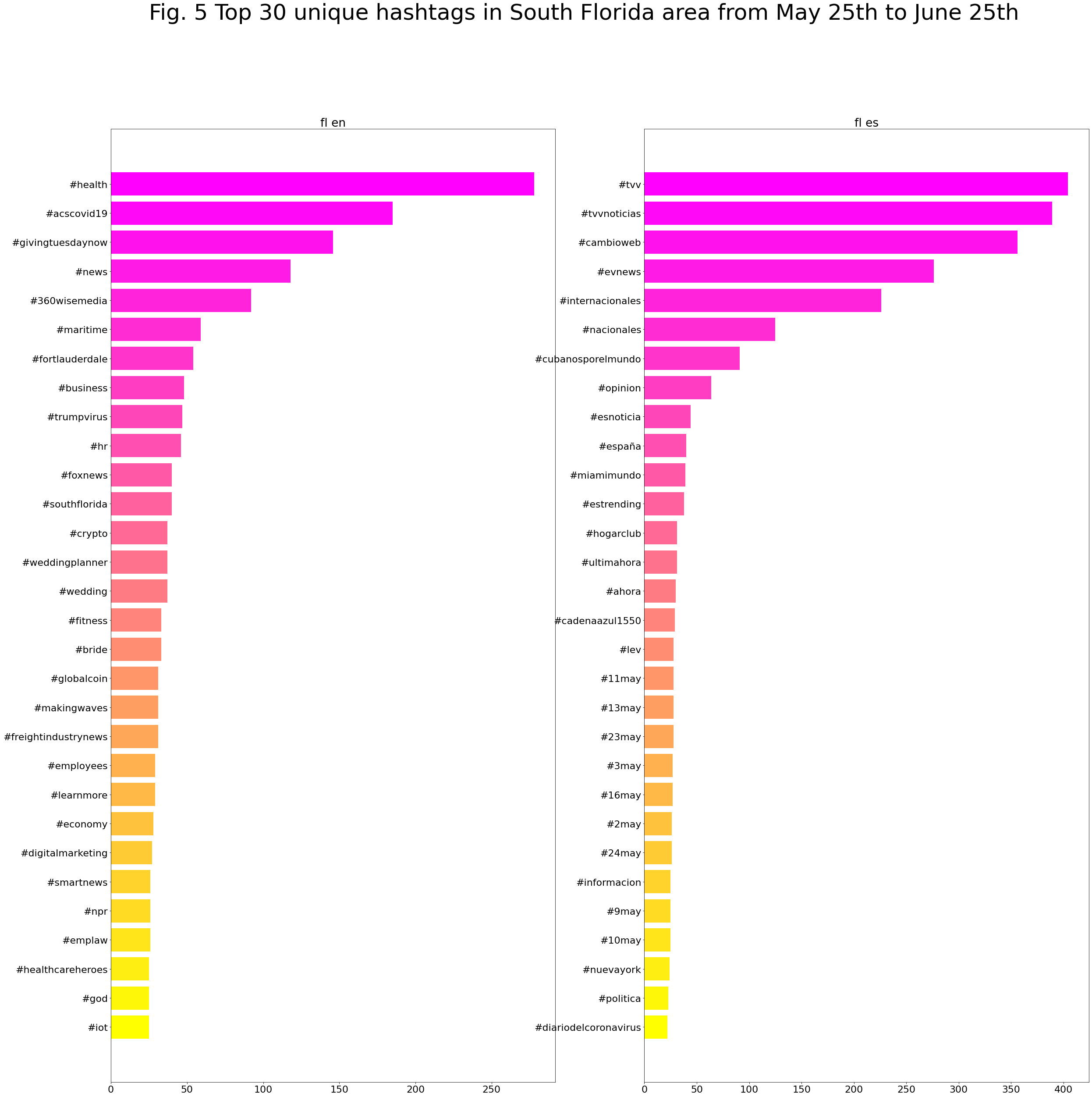
While this plot bar shows the top unique hashtags from May 25th to June 25th:
We hope, with this blog post, to have shown some more techniques on how to explore our Twitter corpus. Stay tuned for more functionalities and more thoughts about what people are saying about Covid-19 on social media.