
El discurso público generado en Twitter es uno de los principales focos de atención en nuestro proyecto de investigación. Asimismo, la gran cantidad de datos de Twitter ha atraído el interés de investigadores de disciplinas y campos diversos para explorar diferentes aspectos de la sociedad. Esta entrada se concibe a modo de tutorial sobre cómo usar DocNow Hydrator con el fin de “hidratar” los tweets. Nuestro proyecto, como ya hemos indicado, está ofreciendo una serie de datasets o conjuntos de datos, que recogen tweets relacionados con la Covid-19 y que pueden ser descargados desde nuestro respositorio de GitHub.
Debido a los términos de desarrollo de Twitter y a la ética de investigación, la mayoría de los TweetSets (conjunto de datos de Twitter) que podemos extraer de la Interfaz de Programación de Aplicaciones (API) de Twitter así como de las bases de datos de terceros son tweets “deshidratados”. En otras palabras, en lugar de recopilar el contenido de los tweets, las geolocalizaciones, el tiempo, las imágenes y otra información sobre los tweets, lo que los investigadores obtienen es un archivo de texto plano que consiste en una lista de identificadores únicos de cada uno de los tweets (tweets IDs). Estos IDs permiten recuperar todos los metadatos del tweet, incluyendo el texto, y deben ser “hidratados” para recuperar los metadatos y convertirse en una fuente significativa de investigación. El gran tamaño de los metadatos relacionados con cada uno los tweets es una de las razones principales por las que los datasets ofrecen solo identificadores “deshidratados”. Así, un archivo que ofrece sólo una serie de números (IDs) es mucho más manejable que, por ejemplo, una hoja csv con miles de tweets con sus metadatos.
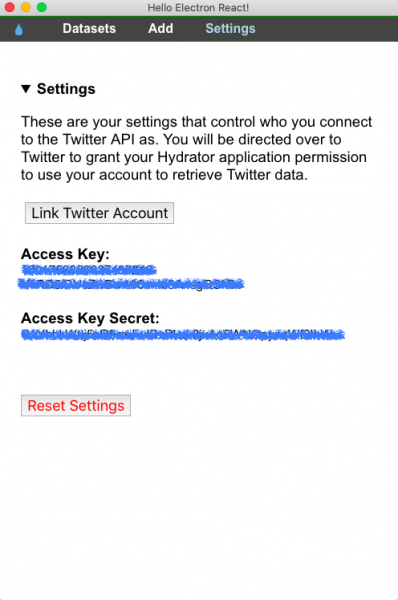
DocNow Hydrator es un programa de código abierto utilizado para hidratar las identificadores de los tweets, y puede descargarse desde Github. Antes de comenzar a utilizar Hydrator debemos vincular nuestra cuenta de Twitter en “Settings” (Configuración).
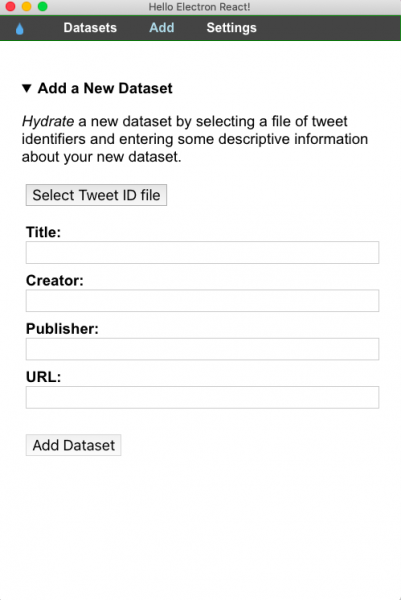
Una vez que Hydrator está configurado, puedes subir tu archivo de identificadores de tweets. En nuestro caso, utilizamos nuestro conjunto de datos sobre las Narrativas Digitales de la Covid-19, que actualizamos diariamente.
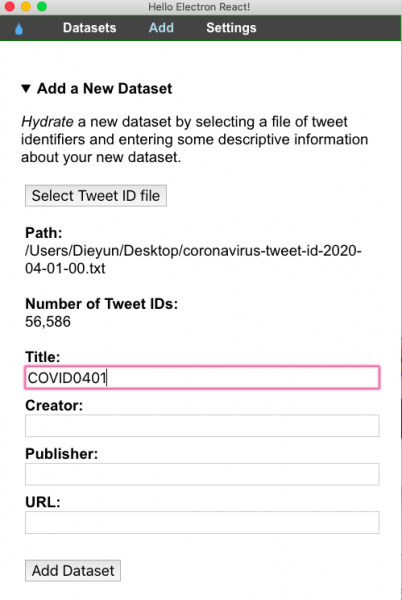
Si tu archivo ha sido procesado correctamente, Hydrator te mostrará la ruta del archivo y calculará el número total de tweet IDs detectados. En “Title” (título) puedes renombrar el archivo hidratado, mientras que el resto de las casillas pueden ser ignoradas. Luego haz clic en “Add dataset” (añadir conjunto de datos).
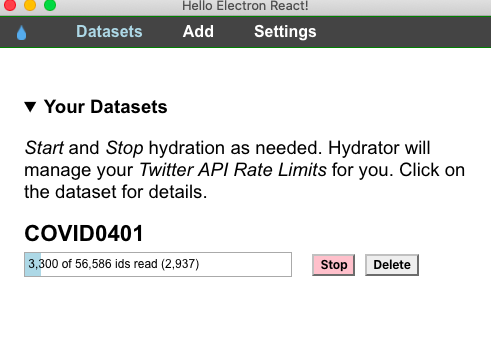
Haz clic en “Start” para hidratar las tweet IDs.
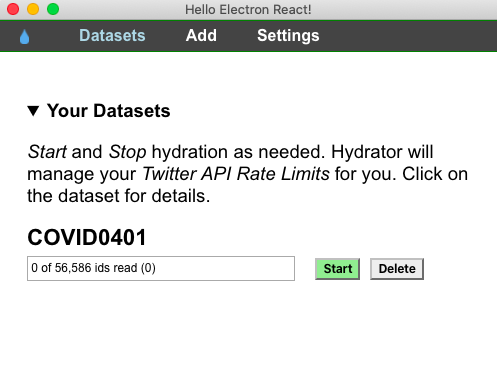
Aparecerá una nueva pestaña que te solicitará ubicación y nombre para el archivo de tweets IDs hidratados. Hydrator generará un archivo .json por defecto. Convertir el documento en un archivo .csv lo hará más accesible para ser consultado por Excel u otros procesadores de archivos.
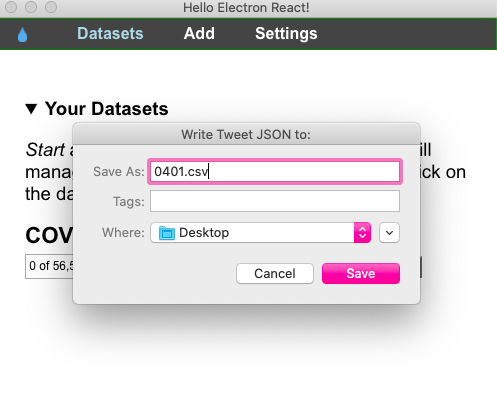
Hydrator comenzará el proceso de hidratación. El tiempo de ejecución dependerá de la cantidad de tweet IDs.
El archivo .csv completo presentará toda la información relacionada a los tweet IDs originales.
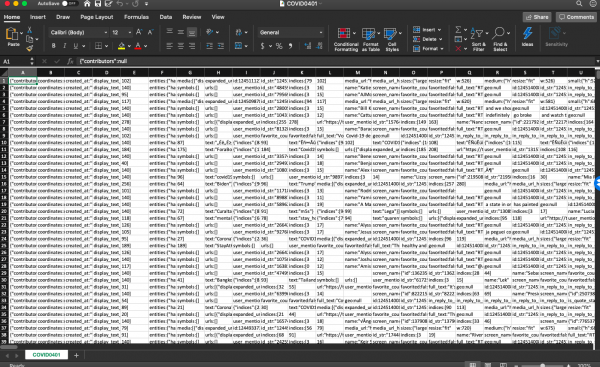
Con ello, los investigadores pueden analizar geolocalizaciones, imágenes, emojis, el discurso delos tweets, hashtags, información temporal, así como otra relacionada con metadatos. Si utilizas nuestro conjunto de datos, nos gustaría mucho que compartieras tu experiencia con nosotros. !Síguenos en nuestro blog y gracias por mantenerte al día con nuestro proyecto!